[LeetCode-中级]删除排序链表中的重复元素
问题描述
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字。
示例 1:
输入: 1->2->3->3->4->4->5 输出: 1->2->5
示例 2:
输入: 1->1->1->2->3 输出: 2->3
问题的描述是删除重复的节点。在解决这个问题之前,我们先解决一个简单的问题,问题描述如下:
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
示例 1:
输入: 1->1->2 输出: 1->2
示例 2:
输入: 1->1->2->3->3 输出: 1->2->3
解题思路
对于仅保留一个重复元素的问题,我们可以每个节点依次与其下一个节点比较,如下:
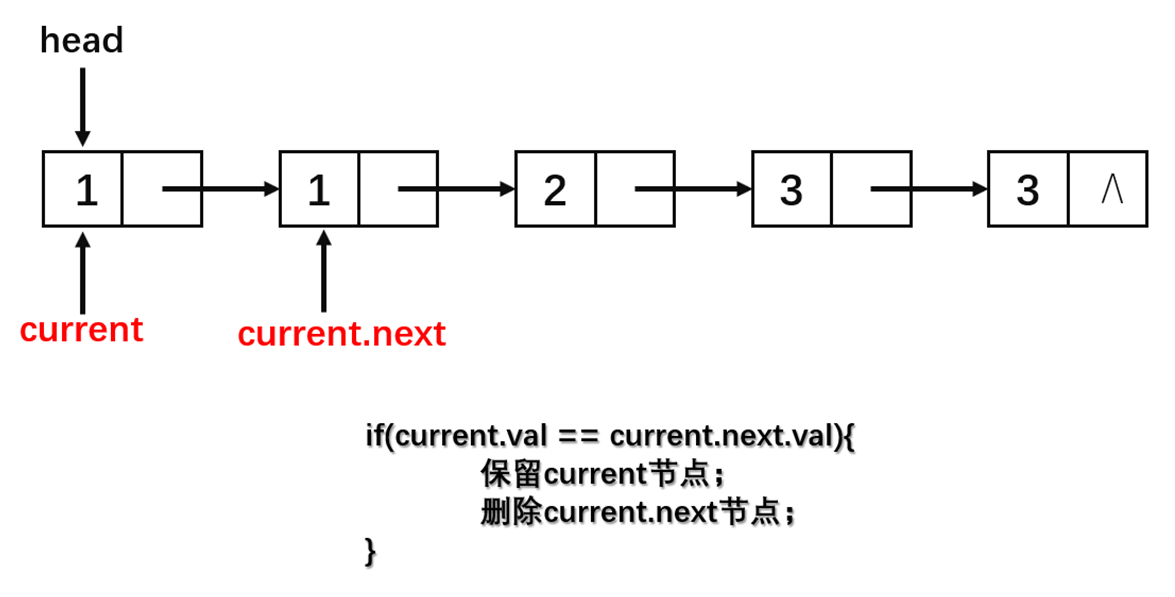
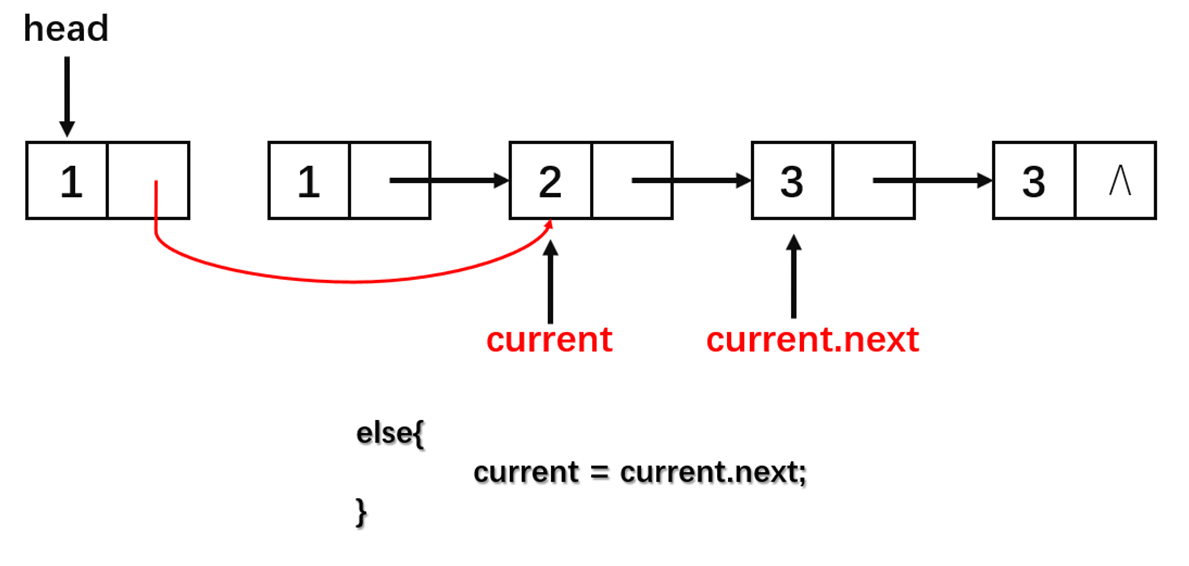
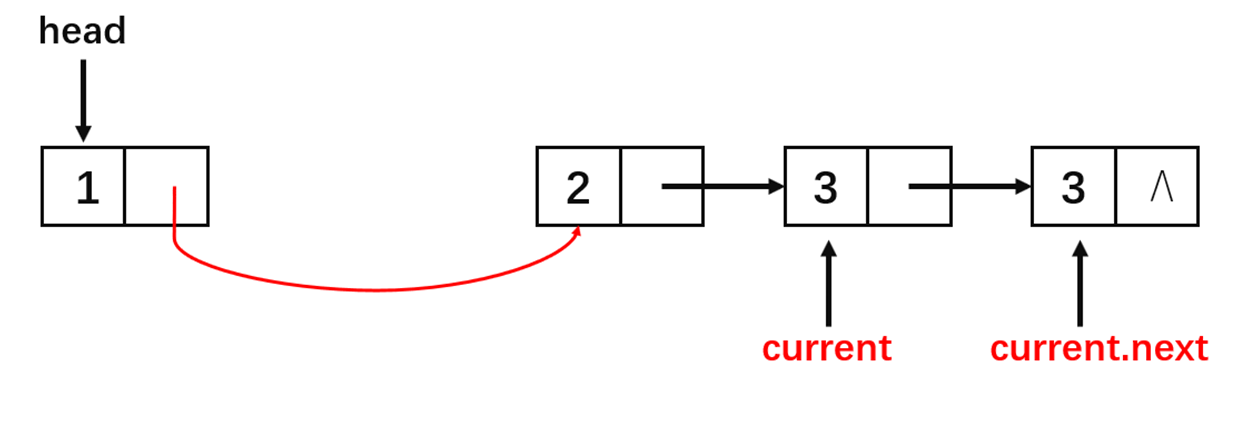
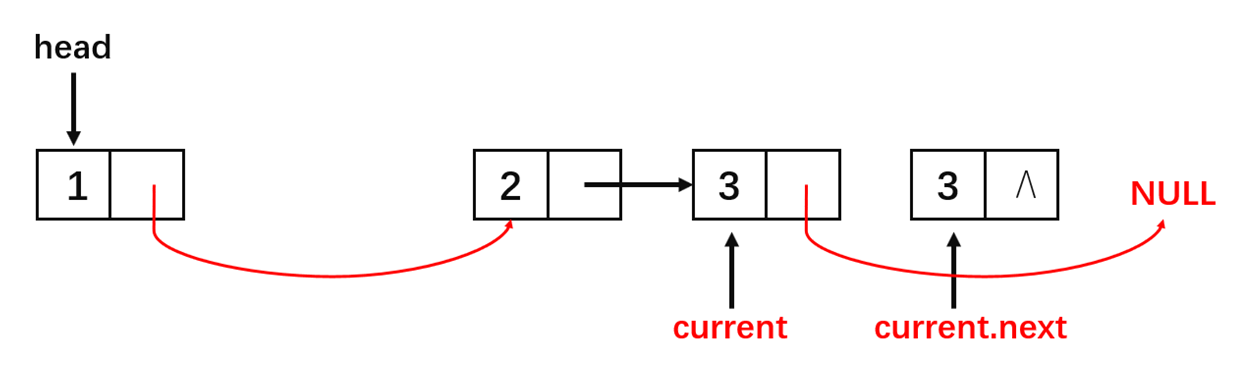
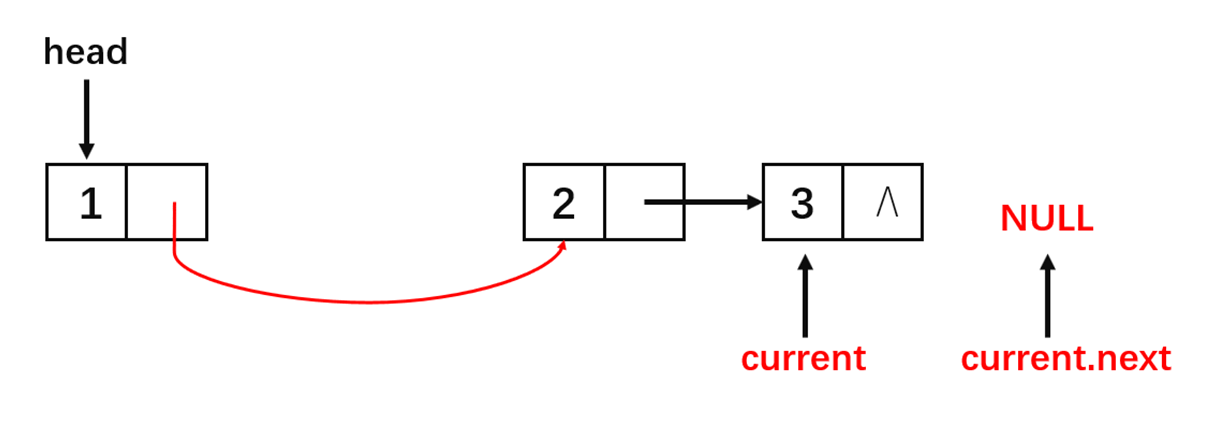
从图中可以看到整个算法的流程很简单,算法的实现如下:
class Solution:
def deleteDuplicates(self, head: ListNode) -> ListNode:
current = head
while current and current.next:
if current.val == current.next.val:
current.next = current.next.next
else:
current = current.next
return head我们回头再来看标题的问题,我们使用什么样的手法将出现重复的节点全部删除呢?解决思路和上面这个问题的思路不太相同。换个角度想,我们也要删除第一次出现的节点,这是我们需要在这之前再定义一个变量。
基本思路就是每一次区间[l,r)(左闭右开)中的数字相同,然后判断该区间的长度是否为1,若长度为1则通过尾插法插入到答案中(这一步看图)。
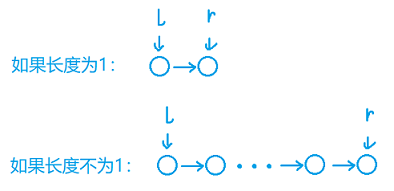
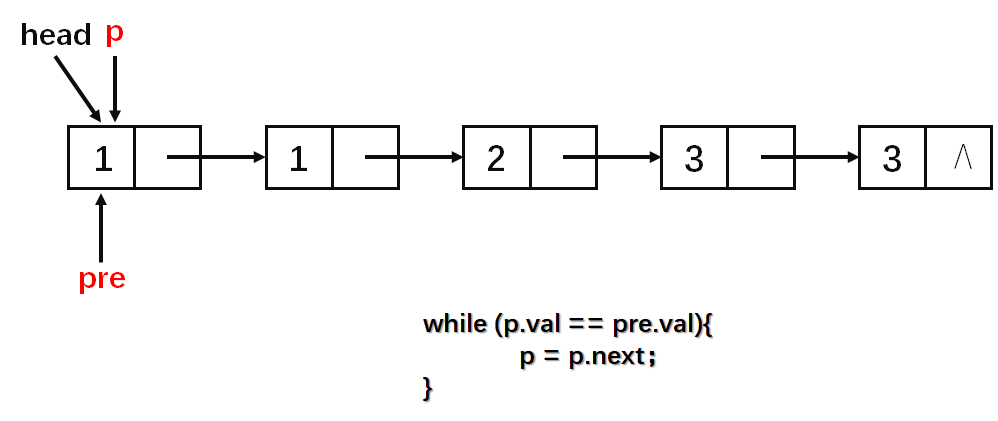
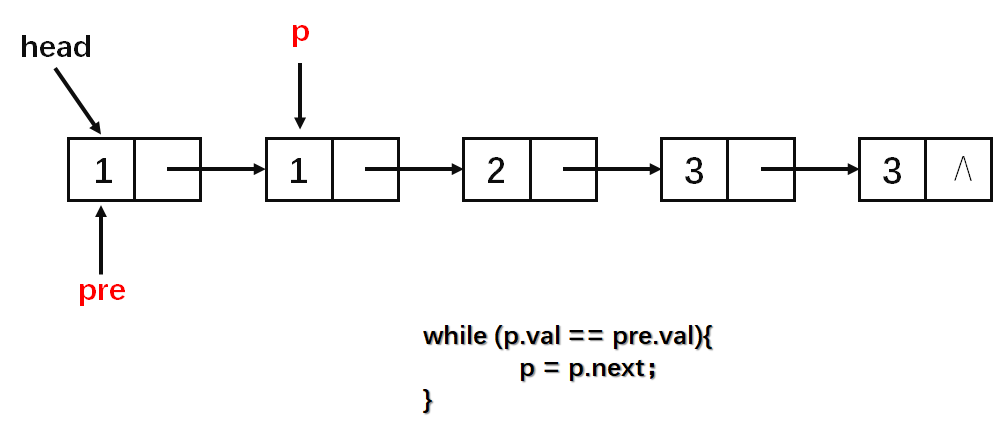
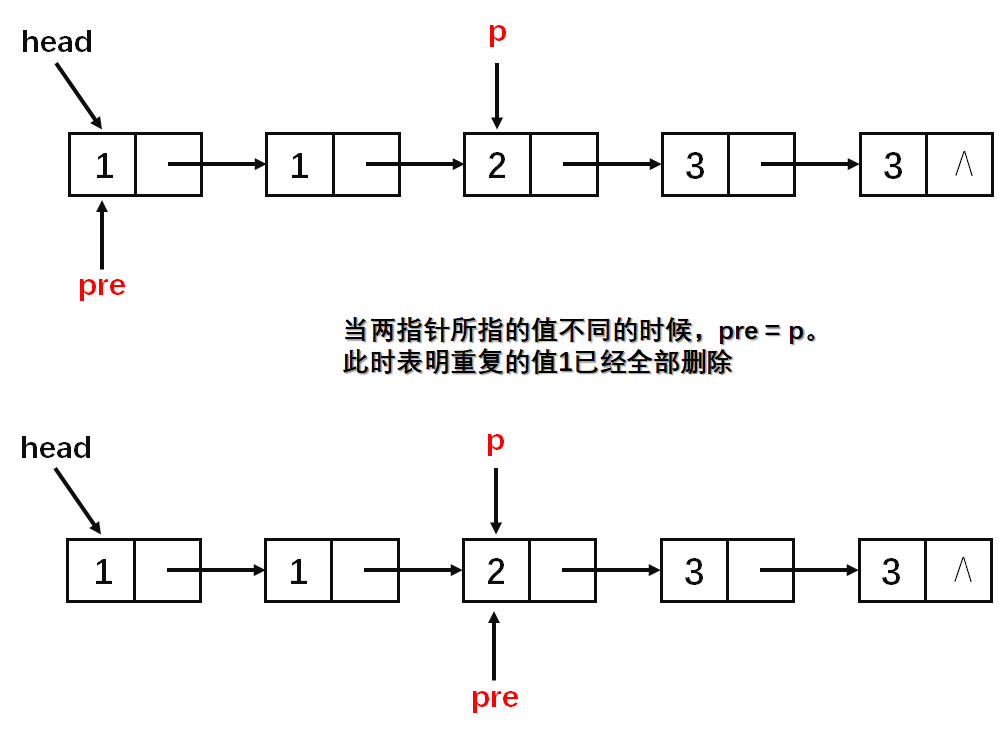
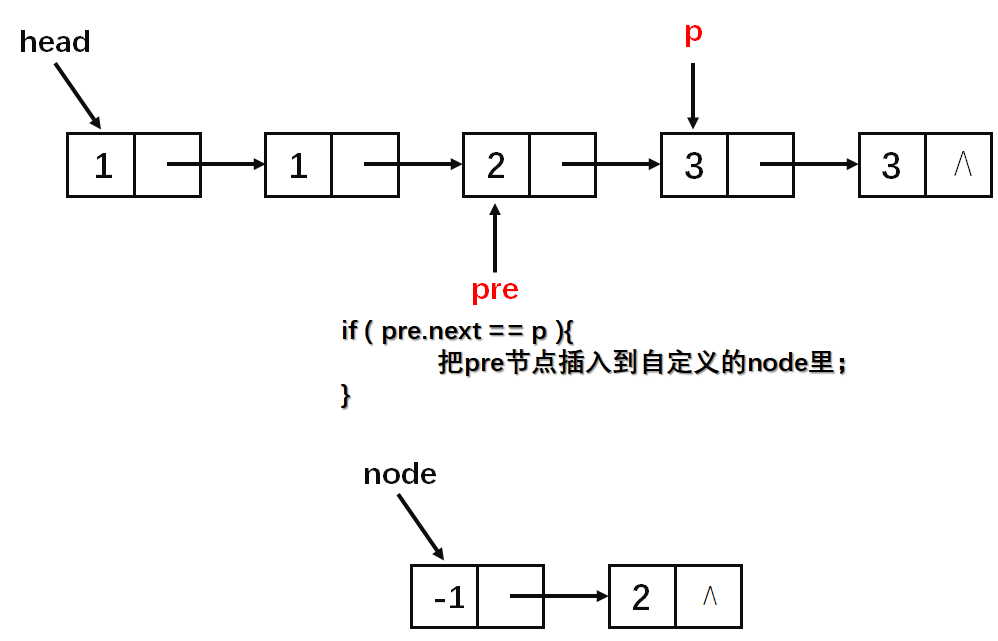
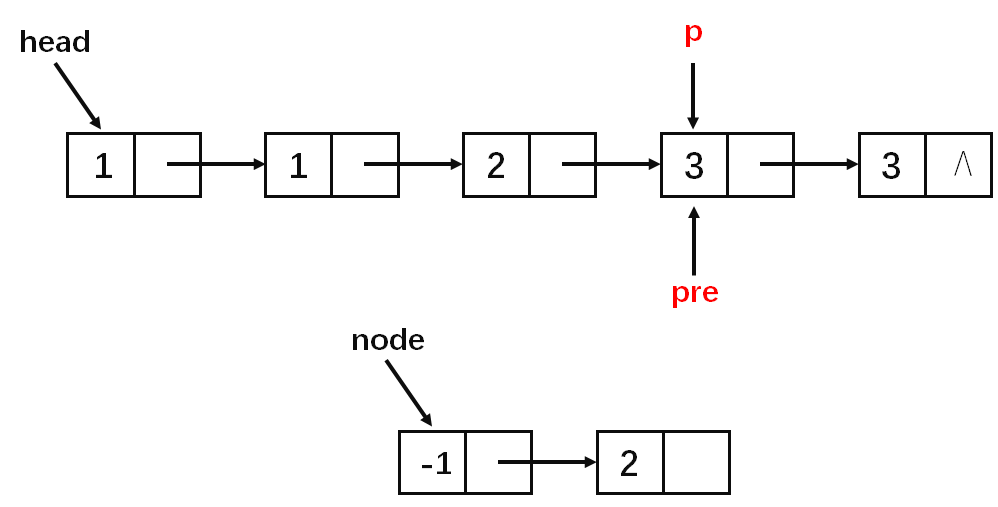
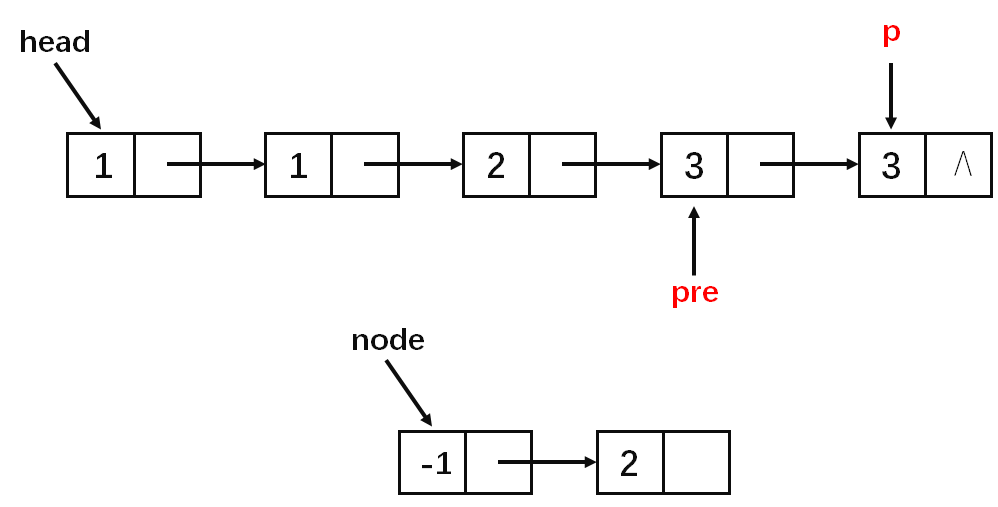
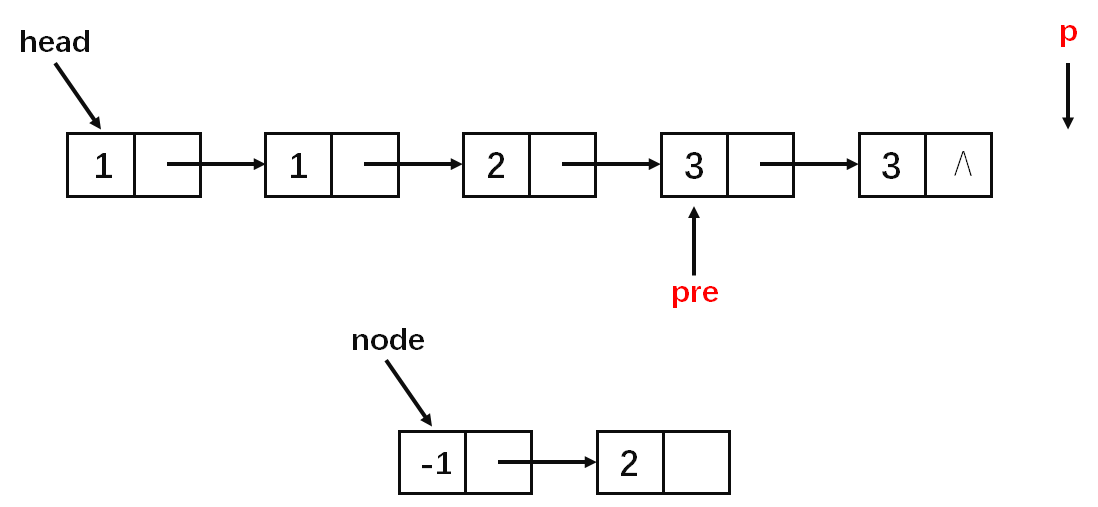
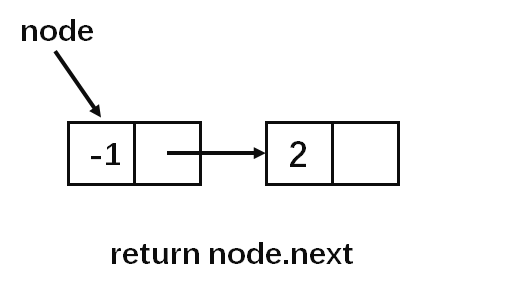
算法实现
class Solution:
def deleteDuplicates(self, head: ListNode) -> ListNode:
pre = head
p = head
node = ListNode(-1)
tail = node
while pre and p:
while p and pre.val == p.val:
p = p.next
if pre.next == p:
tail.next = pre
tail = pre
tail.next = None
pre = p
return node.next这道题需要思考的地方就是如何将重复的节点全部略过去,算法的时间复杂度是n,并不是n^2!!! 外层循环控制扫描整个链表,内部循环负责移动指针避开所有重复的节点。这种算法并没有进行原地操作,取而代之的是新建了链表,将不重复的元素尾插到新的链表中,最后返回这个新的链表。当然对于这种题目来说,第一反应可能得到的不是最优的解法。
附录
在结题的过程中,我页参考了其他人的一些做法,算法实现如下:
这里要求的是去重,那简单。用一个哈希表记录每个值出现的频率就可以了。
具体做法如下:
- 遍历链表,将每个节点的值放到哈希表中,哈希表的key就是节点的值,value是这个值出现的频率
- 遍历哈希表,将所有频率==1的key放到集合中
- 对集合进行排序
- 遍历集合,然后不断创建新的链表节点
当然这里可以优化一下,比如使用LinkedHashMap或者OrderedDict这样的数据结构,可以省去排序环节。
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if(head==null || head.next==null) {
return head;
}
//用哈希表记录每个节点值的出现频率
HashMap<Integer,Integer> cache = new HashMap<Integer,Integer>();
ArrayList<Integer> arr = new ArrayList<Integer>();
ListNode p = head;
while(p!=null) {
int val = p.val;
if(cache.containsKey(val)) {
cache.put(val,cache.get(val)+1);
} else {
cache.put(val,1);
}
p = p.next;
}
//将所有只出现一次的值放到arr中,之后再对这个arr排序
for(Integer k : cache.keySet()) {
if(cache.get(k)==1) {
arr.add(k);
}
}
Collections.sort(arr);
ListNode dummy = new ListNode(-1);
p = dummy;
//创建长度为arr.length长度的链表,依次将arr中的值赋给每个链表节点
for(Integer i : arr) {
ListNode tmp = new ListNode(i);
p.next = tmp;
p = p.next;
}
return dummy.next;
}
}本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!