Python & OpenCV Quick Start
为什么使用Python-OpenCV ?
虽然python 很强大,而且也有自己的图像处理库PIL,但是相对于OpenCV 来讲,它还是弱小很多。跟很多开源软件一样OpenCV 也提供了完善的python 接口,非常便于调用。OpenCV 的稳定版是2.4.8,最新版是3.0,包含了超过2500 个算法和函数,几乎任何一个能想到的成熟算法都可以通过调用OpenCV 的函数来实现,超级方便。
第1章 opencv基本操作
1.1 打开图片
使用函数cv2.imread() 读入图像。这幅图像应该在此程序的工作路径,或者给函数提供完整路径,第二个参数是要告诉函数应该如何读取这幅图片。
• cv2.IMREAD_COLOR:读入一副彩色图像。图像的透明度会被忽略, 这是默认参数。
• cv2.IMREAD_GRAYSCALE:以灰度模式读入图像
import cv2
img = cv2.imread('lena.jpg',0)PS:调用opencv,就算图像的路径是错的,OpenCV 也不会提醒你的,但是当你使用命
令print img时得到的结果是None。
1.2 显示图片
使用函数cv2.imshow() 显示图像。窗口会自动调整为图像大小。第一个参数是窗口的名字,其次才是我们的图像。你可以创建多个窗口,只要你喜欢,但是必须给他们不同的名字。
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows() #dv2.destroyWindow(wname)cv2.waitKey顾名思义等待键盘输入,单位为毫秒,即等待指定的毫秒数看是否有键盘输入,若在等待时间内按下任意键则返回按键的ASCII码,程序继续运行。若没有按下任何键,超时后返回-1。参数为0表示无限等待。不调用waitKey的话,窗口会一闪而逝,看不到显示的图片。cv2.destroyAllWindow()销毁所有窗口cv2.destroyWindow(wname)销毁指定窗口
1.3 保存图片
使用函数cv2.imwrite(file,img,num)保存一个图像。第一个参数是要保存的文件名,第二个参数是要保存的图像。可选的第三个参数,它针对特定的格式:对于JPEG,其表示的是图像的质量,用0 - 100的整数表示,默认95;对于png ,第三个参数表示的是压缩级别。默认为3.
注意:
cv2.IMWRITE_JPEG_QUALITY类型为 long ,必须转换成 intcv2.IMWRITE_PNG_COMPRESSION, 从0到9 压缩级别越高图像越小。
cv2.imwrite('1.png',img, [int( cv2.IMWRITE_JPEG_QUALITY), 95])
cv2.imwrite('1.png',img, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])1.4 图片操作
1. 翻转图像
使用函数cv2.flip(img,flipcode)翻转图像,flipcode控制翻转效果。
flipcode = 0:沿x轴翻转
flipcode > 0:沿y轴翻转
flipcode < 0:x,y轴同时翻转
imgflip = cv2.flip(img,1)2. 复制图像
imgcopy = img.copy()第2章 计算机视觉入门
2.11 tensorflow常量变量定义
定义一个data的常量,取值为2
import tensorflow as tf
data1 = tf.constant(2,dtype=tf.int32)
session = tf.Session()
print(data1)
print(session.run(data1))输出结果如下:
Tensor("Const:0", shape=(), dtype=int32)
2直接输出data1对象,并不能输出2,而是输出data1的tensorflow描述信息。
在定义一个变量,命名为var。像其他语言一样,要是有变量之前,要对该变量进行初始化。
import tensorflow as tf
data2 = tf.Variable(10,name='var')
session = tf.Session()
init = tf.global_variables_initializer() #初始化
session.run(init)
print(session.run(data2))先初始化变量,然后再输出变量:
102.12 tensorflow运算原理
tensorflow的实质:张量tensor + 计算图graphs
张量表示的就是数据,可以是常量,可以是变量
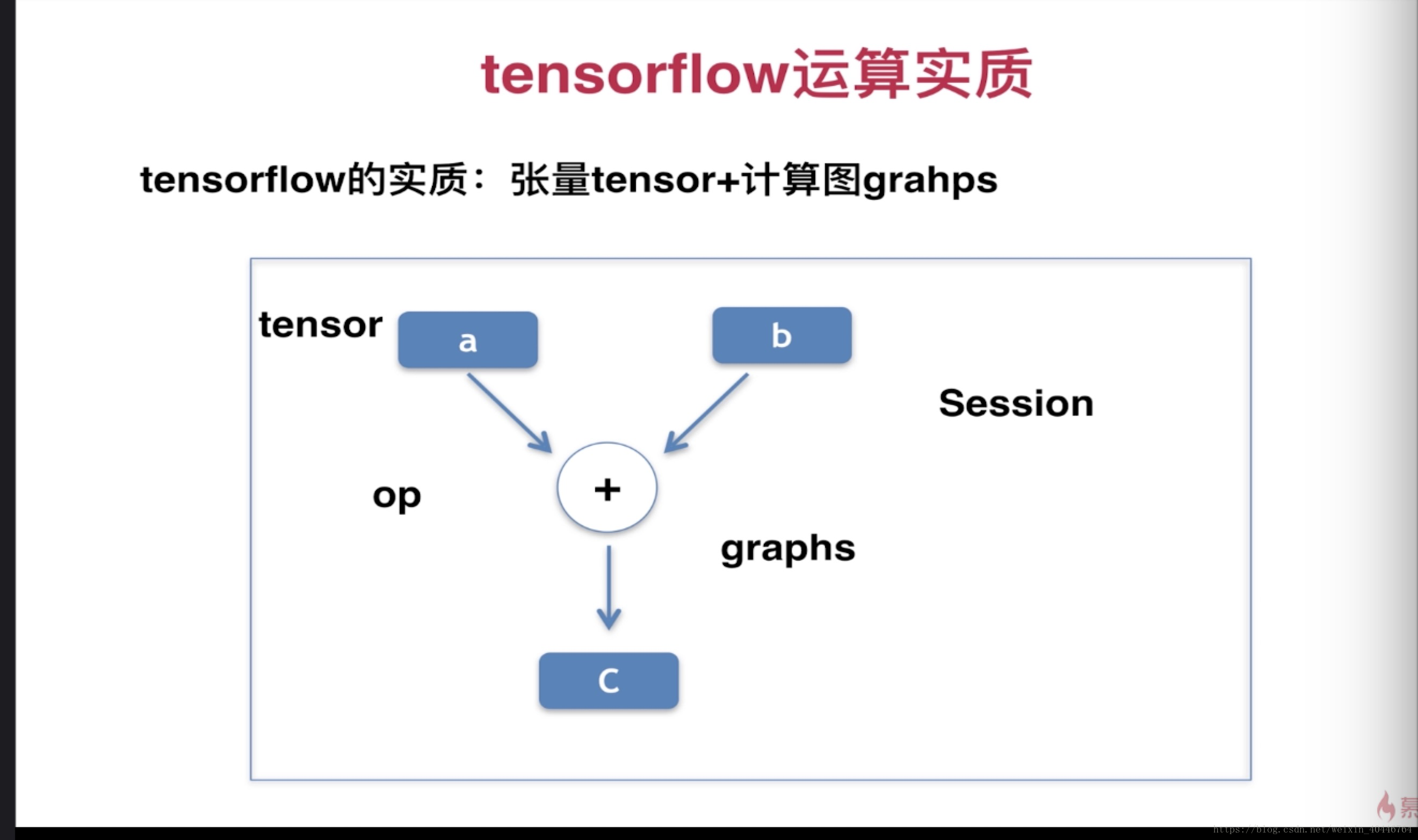
本质 tf = tensor + 计算图
tensor数据,op可以是赋值运算或加减运算,计算图就是张量和运算一起的结构
在tf中,所有的计算图(graphs)都要放在会话(session)中来执行,所有session是执行的核心,可以理解为运算的一个交互环境。需要把当前的交互环境放到session中,使用它的run()方法。比如上一个例子中的:
session.run(data1) #data1为张量
session.run(init) #init理解为op最后,使用完session后要关闭
session.close()如果不主动关闭session的话,可以使用with关键字
import tensorflow as tf
data = tf.constant('hello world!')
session = tf.Session()
with session:
out = session.run(data)
print(out)2.13 常量变量的四则运算
常量的四则运算
import tensorflow as tf
data1 = tf.constant(6)
data2 = tf.constant(2)
dataAdd = tf.add(data1,data2) #加法
dataMultiply = tf.multiply(data1,data2) #乘法
dataSubtraction = tf.subtract(data1,data2) #减法
dataDivision = tf.divide(data1,data2) #除法
with tf.Session() as session:
print(session.run(dataAdd))
print(session.run(dataMultiply))
print(session.run(dataSubtraction))
print(session.run(dataDivision))
print("End!............")输出结果:
8
12
4
3.0
End!............常量与变量的四则运算
data1 = tf.constant(6)
data2 = tf.Variable(2) #改为变量
dataAdd = tf.add(data1,data2)
dataMultiply = tf.multiply(data1,data2)
dataSubtraction = tf.subtract(data1,data2)
dataDivision = tf.divide(data1,data2)
init = tf.global_variables_initializer() #初始化
with tf.Session() as session:
session.run(init) #初始化
print(session.run(dataAdd))
print(session.run(dataMultiply))
print(session.run(dataSubtraction))
print(session.run(dataDivision))
print("End!............")输出结构与上面的相同
下面说下assign()函数的使用:
import tensorflow as tf
num1 = tf.Variable(tf.constant(6)) #tensor
num2 = tf.Variable(tf.constant(3)) #tensor
dataMultiply1 = tf.multiply(num1,num2) #op->graphs
dataMultiply2 = tf.multiply(num1,num2) #op->graphs
with tf.Session() as session:
session.run(tf.global_variables_initializer())
print(session.run(dataMultiply1))
print('DataCopy: ', session.run(tf.assign(num2,dataMultiply1))) #将dataMultiply1的结果赋值给num2中
print(session.run(dataMultiply2))事实上,tf.assign(ref, new_value)函数返回的结果就是参数中的new_value,因此我们只需要用ref来接收返回值也可以达到直接更新的效果。上图中可以很好的看清tensorflow的执行原理。
下面说下eval()的使用:
import tensorflow as tf
num1 = tf.Variable(tf.constant(3)) #tensor
num2 = tf.Variable(tf.constant(2)) #tensor
dataMultiply1 = tf.multiply(num1,num2) #op->graphs
dataMultiply2 = tf.multiply(num1,num2) #op->graphs
with tf.Session() as session:
session.run(tf.global_variables_initializer())
print(session.run(dataMultiply1))
print('DataCopy: ', session.run(tf.assign(num2,dataMultiply1))) #将dataMultiply1的结果赋值给num2中
print('Eval: ',tf.assign(num2,dataMultiply1).eval())
print(session.run(dataMultiply2))输出结果:
6
DataCopy: 6
Eval: 18
54eval() 其实就是tf.Tensor的Session.run() 的另外一种写法,但两者有差别
- eval(): 将字符串string对象转化为有效的表达式参与求值运算返回计算结果
- eval()也是启动计算的一种方式。基于Tensorflow的基本原理,首先需要定义图,然后计算图,其中计算图的函数常见的有run()函数,如sess.run()。同样eval()也是此类函数,
- 要注意的是,eval()只能用于tf.Tensor类对象,也就是有输出的Operation。对于没有输出的Operation, 可以用.run()或者Session.run();Session.run()没有这个限制。
placeholder的使用
data1 = tf.placeholder(tf.float32)
data2 = tf.placeholder(tf.float32)
dataAdd = tf.add(data1,data2)
with tf.Session() as session:
print(session.run(dataAdd,feed_dict={data1:6,data2:2}))
#1 dataAdd 2 data(feed_dict={1:6,2:2})输出:
8.02.14 矩阵基础
详细见numpy教程
第3章 计算机视觉加强之几何变换
3.1 图片缩放
import cv2
img = cv2.imread('timg.jpg', 1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
channel = imgInfo[2]
factor = 0.5
#1. 放大 缩小 2. 等比例 非等比例缩放
dstHeight = int(height*factor)
dstWidth = int(width*factor)
dst = cv2.resize(img, (dstWidth, dstHeight))
cv2.imshow('Pineapple',dst)
cv2.waitKey(0)
cv2.destroyAllWindows() # esc可退出,不然会busy图片的宽高都乘以了一个缩放因子factor实现图片的等比例缩放
下面讲解图像的四种缩放方法:
- 最近邻域插值
- 双线性插值
- 像素关系重采样
- 立方插值
1.最近邻域插值
假设有一个10×20 的图片,我们要缩放到 5×10(记为dst),那么dst中的每一个点都来自于原图片,比如dst中(1,2)<– (2,4)
那么我们如何计算并找到这些点呢?
即已知dst中的点,要求出原图片中的点。这里有个公式:
$$
srcX=dstX* (srcWidth/dstWidth)
$$
例如,想要计算目标图片中 x为 1 的点对应的是原图像中的哪个点的x值
srcX = 1 * (10 / 5) = 2
同样的,
$$
srcY = dstY * (srcHeight/dstHeight)
$$
srcY = 2 * (20 / 10) = 4
有时,我们计算出来的结果并不为整数,例如 12.3 ,则取最近的像素 12,
这种方法即为最近临域。
import cv2
import numpy as np
#1. info
img = cv2.imread('timg.jpg',1)
imgInfo = img.shape
print(imgInfo)
height = imgInfo[0]
width = imgInfo[1]
dstHeight = int(height/2)
dstWidth = int(width/2)
#最近邻域插值
dstImg = np.zeros((dstHeight, dstWidth, 3), np.uint8)
for i in range(0,dstHeight): #row number
for j in range(0,dstWidth): #column number
iNew = int(i*(height*1.0/dstHeight))
jNew = int(j*(width*1.0/dstWidth))
dstImg[i, j] = img[iNew, jNew]
print(dstImg.shape)
cv2.imshow('dest', dstImg)
cv2.waitKey(0)其他算法在这里不介绍
3.2 图片剪切
import cv2
img = cv2.imread('timg.jpg',1)
imgInfo = img.shape
print(imgInfo)
dst = img[100:200, 100:300]
cv2.imshow('dst',dst)
cv2.waitKey(0)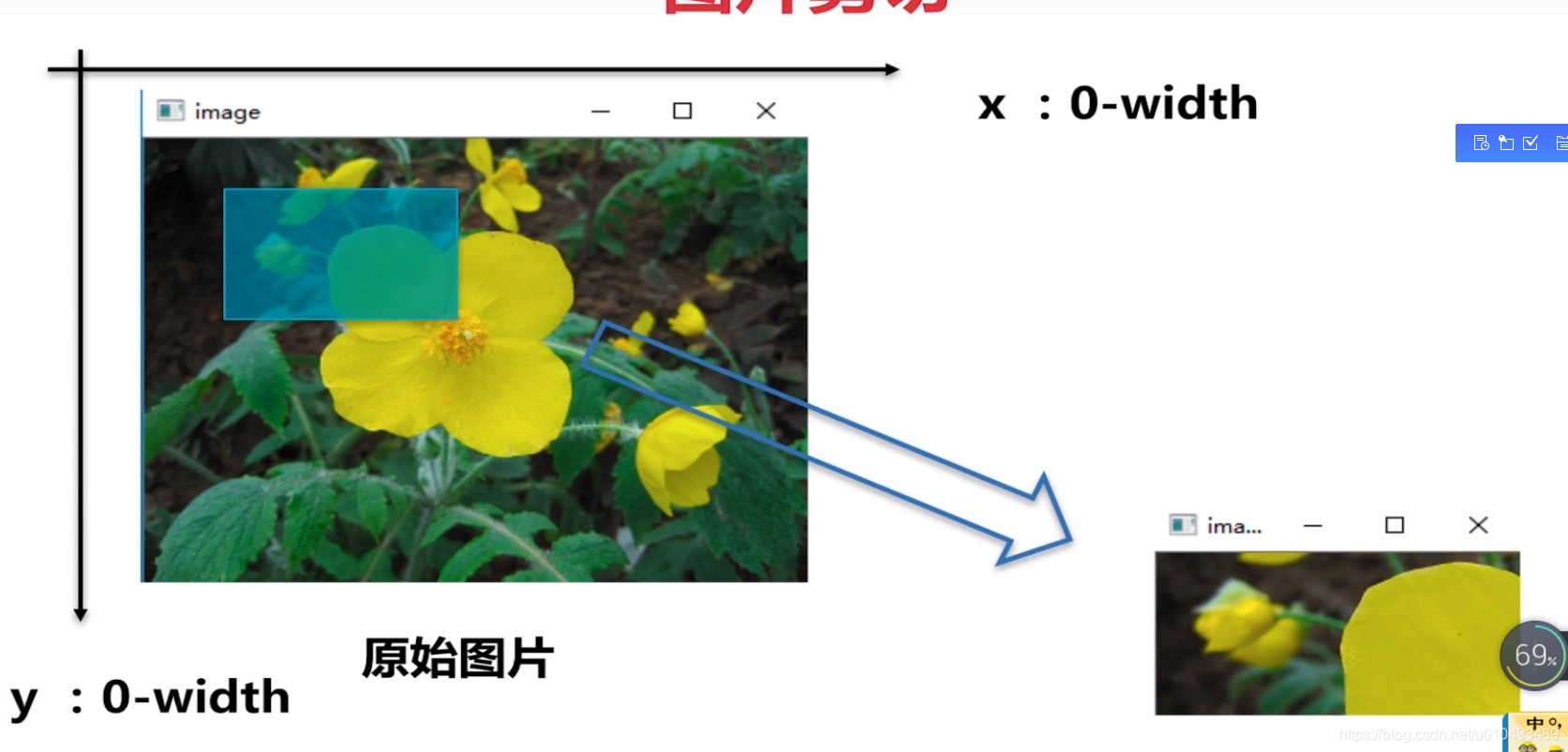
3.3 图片移位
import cv2
import numpy as np
img = cv2.imread('timg.jpg', 1)
cv2.imshow('src', img)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
matShift = np.float32([[1, 0, 100], [0, 1, 200]])#2*3
# 1 data 2 mat 3 info
#完成位移和矩阵的运算
dst = cv2.warpAffine(img, matShift, (height, width))
cv2.imshow('dst', dst)
cv2.waitKey(0)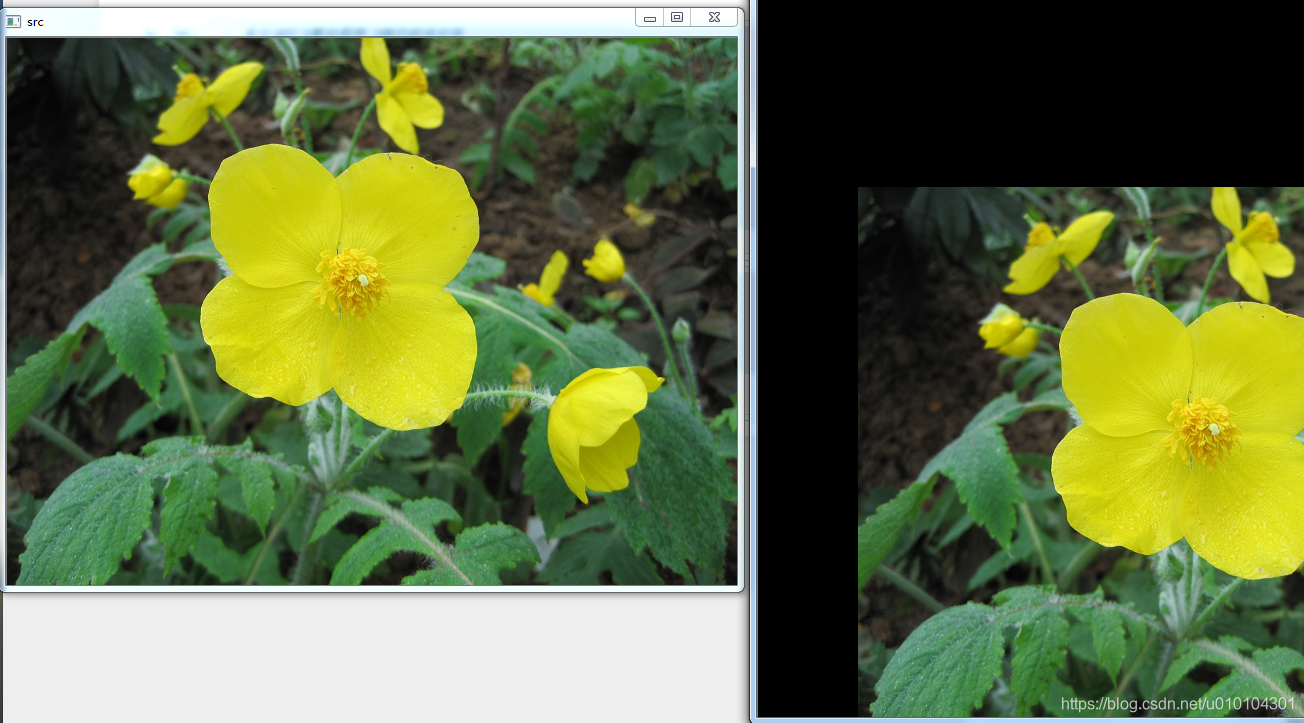
API级别的移位实现原理:

代码实现图像的位移,其实就是将x,y分别移动位置:
import cv2
import numpy as np
img = cv2.imread('timg.jpg', 1)
cv2.imshow('src', img)
imgInfo = img.shape
dst = np.zeros(img.shape, np.uint8)
height = imgInfo[0]
width = imgInfo[1]
for i in range(0, height):
for j in range(0, width-100):
dst[i, j+100] = img[i, j]
cv2.imshow('dst', dst)
cv2.waitKey(0)
3.4 图像镜像
import cv2
import numpy as np
img = cv2.imread('timg.jpg', 1)
cv2.imshow('src', img)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
channel = imgInfo[2]
newImgInfo = (height*2, width, channel)
dst = np.zeros(newImgInfo, np.uint8)
#反转图像填充
for i in range(0,height):
for j in range(0,width):
dst[i, j] = img[i, j]
# x不变 y = 2*h -y -1
dst[height*2-i-1, j] = img[i, j]
#添加水平分割线
for i in range(0,width):
dst[height, i] = (0, 0, 255)
cv2.imshow('dst', dst)
cv2.waitKey(0)
3.5 图片仿射变换
import cv2
import numpy as np
img = cv2.imread('timg.jpg', 1)
cv2.imshow('src', img)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
#src中的3个点转换到dst中的3个新点,然后确定唯一的图像平面
matSrc = np.float32([[0, 0], [0, height-1], [width-1, 0]])
matDst = np.float32([[50, 50], [300, height-200], [width-300, 100]])
#组合
matAffine = cv2.getAffineTransform(matSrc, matDst)
dst = cv2.warpAffine(img, matAffine, (width, height))
cv2.imshow('dst', dst)
cv2.waitKey(0)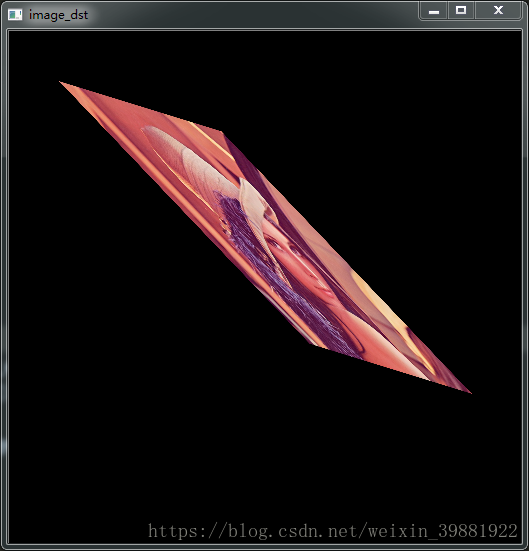
3.6 图片旋转
import cv2
img = cv2.imread('timg.jpg', 1)
cv2.imshow('src', img)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
#Three parameter: center, angle, scale
matRotate = cv2.getRotationMatrix2D((height*0.5, width*0.5), 45, 0.5)
dst = cv2.warpAffine(img,matRotate,(height, width))
cv2.imshow('dst', dst)
cv2.waitKey(0)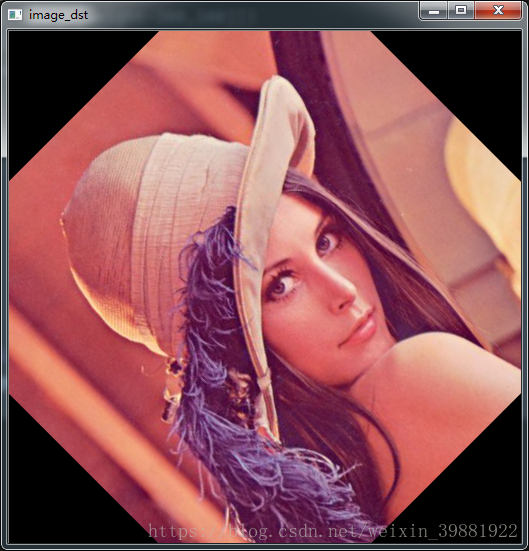
第4章 计算机视觉加强之图像特效
4.1 图像灰度处理
方法一:通过imread读取灰度图片
import cv2
img0 = cv2.imread('timg.jpg',0)
print(img0.shape)
cv2.imshow('img0', img0)
cv2.waitKey(0)方法二:通过cvtColor方法
import cv2
img = cv2.imread('timg.jpg',1)
dst = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cv2.imshow('dst', dst)
cv2.waitKey(0)方法三:RGB取均值方法
import cv2
import numpy as np
img = cv2.imread('timg.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
#RGB三值取相同=gray
dst = np.zeros((height, width,3 ), np.uint8)
for i in range(0,height):
for j in range(0, width):
(B, G, R) = img[i, j]
mean = (int(B)+int(G)+int(R))/3
dst[i, j] = np.uint8(mean)
cv2.imshow('dst', dst)
cv2.waitKey(0)方法四:心理学公式
$$
Gray = R * 0.299 + G * 0.587 + B * 0.114
$$
import cv2
import numpy as np
img = cv2.imread('timg.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
#RGB三值取相同=gray
dst = np.zeros((height, width,3 ), np.uint8)
for i in range(0,height):
for j in range(0, width):
(B, G, R) = img[i, j]
# R = np.float32(R)
# G = np.float32(G)
# B = np.float32(B)
mean = R * 0.299 + G * 0.587 + B * 0.114
dst[i, j] = np.uint8(mean)
cv2.imshow('dst', dst)
cv2.waitKey(0)4.2 算法优化
为什么我们这么强调灰度处理?原因如下:
- 灰度很重要
- 灰度处理很基础
- 能体现出实时性
鉴于此,我们还可以在算法的性能上继续进行优化,往往的经验告诉我们定点数运算快于浮点数运算,加减法运算快于乘除法运算,其中位运算更快。
4.3 图片颜色反转
颜色反转就是用255减去当前的灰度值
彩色图片的颜色反转:
import cv2
import numpy as np
img = cv2.imread('timg.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
dst = np.zeros((height, width, 3), np.uint8)
for i in range(0,height):
for j in range(0, width):
pixels = img[i, j]
dst[i, j] = 255 - pixels #可以直接用255减去,不能写成元组的形式
cv2.imshow('dst', dst)
cv2.waitKey(0)
灰度图片的颜色反转:
import cv2
import numpy as np
img = cv2.imread('timg.jpg',1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
#使用cvtColor函数转化为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dst = np.zeros((height, width, 3), np.uint8)
for i in range(0,height):
for j in range(0, width):
pixels = gray[i, j]
dst[i, j] = 255 - pixels
cv2.imshow('dst', dst)
cv2.waitKey(0)
4.4 马赛克效果
马赛克效果就是将原图进行了一定形状的分割。在每个分割出来的形状中用同一个颜色填充得到。而这个颜色一般取分割得到形状的中心点像素的颜色。
import cv2
img = cv2.imread('timg.jpg', 1)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
for m in range(100, 300):
for n in range(100, 200):
if m % 20 == 0 and n % 20 == 0:
for i in range(0, 20):
for j in range(0, 20):
(B, G, R) = img[m, n]
img[i+m, j+n] = (B, G, R)
cv2.imshow('dst', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
4.5 毛玻璃效果
import cv2
import numpy as np
import random
img = cv2.imread('timg.jpg',1)
cv2.imshow('img', img)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
dst = np.zeros((height, width, 3), np.uint8)
mm = 100
for i in range(0, height):
for j in range(0, width):
num = int(random.random()*mm)
if i + num >= height or j + num >= width: #######
(B, G, R) = img[i - num, j - num]
else:
(B, G, R) = img[i + num, j + num]
dst[i, j] = (B, G, R)
cv2.imshow('dst', dst)
cv2.waitKey(0)注释的地方是为了保证边界处的宽高像素不会产生矩阵越界的错误,这里需要注意!
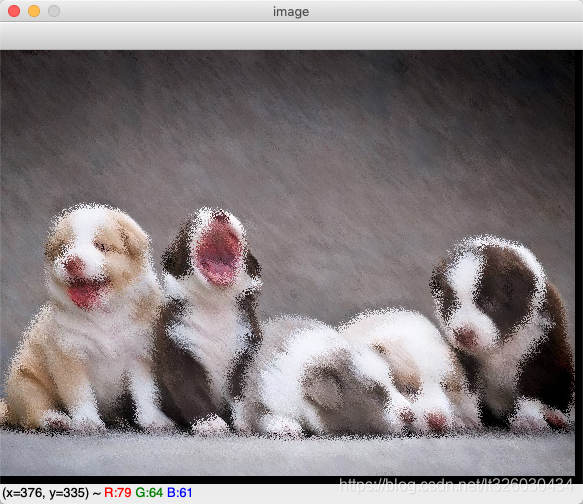
4.6 图像融合效果
import cv2
img1 = cv2.imread('../timg.jpg', 1)
img2 = cv2.imread('../timgjpg.jpg', 1)
dst = cv2.addWeighted(img1, 0.5, img2, 0.5, 0)
cv2.imshow('dst', dst)
cv2.waitKey(0)
cv2.destroyAllWindows()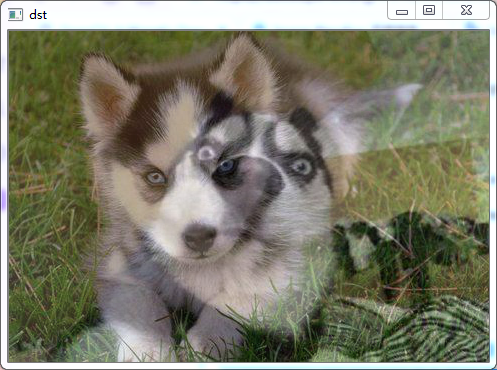
4.7 Canny边缘检测
Canny边缘检测是一种非常流行的边缘检测算法,是John Canny在1986年提出的。它是一个多阶段的算法,即由多个步骤构成。
- 图像降噪
- 计算图像梯度
- 非极大值抑制
- 阈值筛选
OpenCV-Python中Canny函数的原型为:
edge = cv2.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient ]]])必要参数:
- 第一个参数是需要处理的原图像,该图像必须为单通道的灰度图;
- 第二个参数是阈值1;
- 第三个参数是阈值2。
其中较大的阈值2用于检测图像中明显的边缘,但一般情况下检测的效果不会那么完美,边缘检测出来是断断续续的。所以这时候用较小的第一个阈值用于将这些间断的边缘连接起来。
可选参数中apertureSize就是Sobel算子的大小。而L2gradient参数是一个布尔值,如果为真,则使用更精确的L2范数进行计算(即两个方向的倒数的平方和再开放),否则使用L1范数(直接将两个方向导数的绝对值相加)。
import cv2
import numpy as np
img = cv2.imread("D:/lion.jpg", 0)
# 由于Canny只能处理灰度图,所以将读取的图像转成灰度图
img = cv2.GaussianBlur(img,(3,3),0)
# 用高斯平滑处理原图像降噪。若效果不好可调节高斯核大小
canny = cv2.Canny(img, 50, 150)
# 调用Canny函数,指定最大和最小阈值,其中apertureSize默认为3。
cv2.imshow('Canny', canny)
cv2.waitKey(0)
cv2.destroyAllWindows()这个程序只是静态的,下面是可以在运行时调整阈值大小的程序。其代码如下:
import cv2
import numpy as np
def CannyThreshold(lowThreshold):
detected_edges = cv2.GaussianBlur(gray,(3,3),0)
detected_edges =cv2.Canny(detected_edges,lowThreshold,lowThreshold*ratio,apertureSize = kernel_size)
dst = cv2.bitwise_and(img,img,mask = detected_edges) # just add some colours to edges from original image.
cv2.imshow('canny demo',dst)
lowThreshold = 0
max_lowThreshold = 100
ratio = 3
kernel_size = 3
img = cv2.imread('D:/lion.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cv2.namedWindow('canny demo')
cv2.createTrackbar('Min threshold','canny demo',lowThreshold, max_lowThreshold, CannyThreshold)
CannyThreshold(0) # initialization
if cv2.waitKey(0) == 27:
cv2.destroyAllWindows()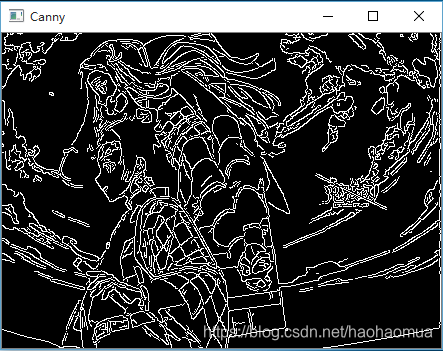
4.8 Sobel边缘检测
Sobel边缘检测算法比较简单,实际应用中效率比canny边缘检测效率要高,但是边缘不如Canny检测的准确,Sobel算子是高斯平滑与微分操作的结合体,所以其抗噪声能力很强,用途较多。尤其是效率要求较高,而对细纹理不太关系的时候,对于一个彩色图要先把它转换为灰度图


核心语句
Sobel_x_or_y = cv2.Sobel(src, ddepth, dx, dy, dst, ksize, scale, delta, borderType)参数:
第一个参数是需要处理的图像;
第二个参数是图像的深度,-1表示采用的是与原图像相同的深度。目标图像的深度必须大于等于原图像的深度;
dx和dy表示的是求导的阶数,0表示这个方向上没有求导,一般为0、1、2。
import cv2
img = cv2.imread('../timg.jpg', 0)
x = cv2.Sobel(img, cv2.CV_16S, 1, 0)
y = cv2.Sobel(img, cv2.CV_16S, 0, 1)
# cv2.convertScaleAbs(src[, dst[, alpha[, beta]]])
# 可选参数alpha是伸缩系数,beta是加到结果上的一个值,结果返回uint类型的图像
Scale_absX = cv2.convertScaleAbs(x) # convert 转换 scale 缩放
Scale_absY = cv2.convertScaleAbs(y)
result = cv2.addWeighted(Scale_absX, 0.5, Scale_absY, 0.5, 0)
cv2.namedWindow("result", 0)
cv2.imshow('result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()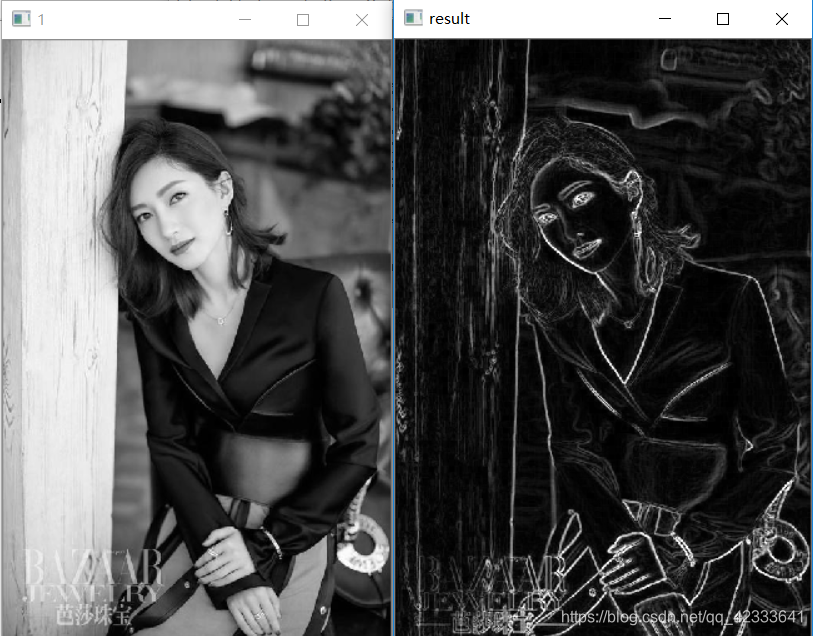
在Sobel函数的第二个参数这里使用了cv2.CV_16S。因为OpenCV文档中对Sobel算子的介绍中有这么一句:“in the case of 8-bit input images it will result in truncated derivatives”。即Sobel函数求完导数后会有负值,还有会大于255的值。而原图像是uint8,即8位无符号数,所以Sobel建立的图像位数不够,会有截断。因此要使用16位有符号的数据类型,即cv2.CV_16S。
在经过处理后,别忘了用convertScaleAbs()函数将其转回原来的uint8形式。否则将无法显示图像,而只是一副灰色的窗口。
result = cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst[, dtype]])其中alpha是第一幅图片中元素的权重,beta是第二个的权重,gamma是加到最后结果上的一个值。
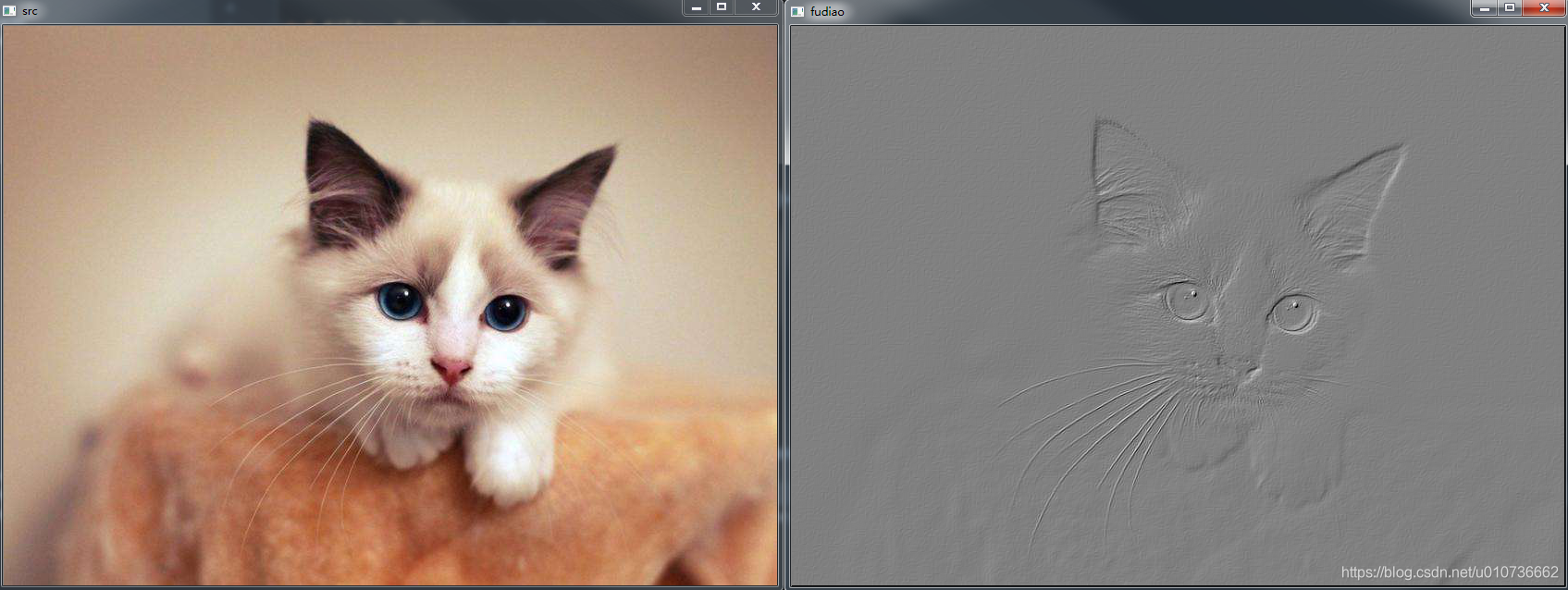
4.9 浮雕和雕刻效果
原理: 根据像素与周围像素的差值确定滤波后的像素值,差别较大的像素(边缘点通常像素差别较大)像素值较大,在灰度图中表现为较亮,边缘凸显,形成浮雕状,然后加上一个灰度偏移值128,作为图片的整体底色。
实现: 浮雕算法是对图像的每一个点进行卷积处理,采用的矩阵如下:
$$
[[1,0],
[0,-1]]
$$
雕刻效果卷积核算子:
$$
[[-1,0],
[0,1]]
$$
import cv2
import numpy as np
# 浮雕和雕刻
img = cv2.imread('../timgjpg.jpg', 1)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
imgInfo = gray_img.shape
height = imgInfo[0]
width = imgInfo[1]
relief_filter = [[1, 0], [0, -1]]
sculpt_filter = [[-1, 0], [0, 1]]
relief_img = np.zeros([height-1, width-1], np.uint8)
sculpt_img = np.zeros([height-1, width-1], np.uint8)
for i in range(0, height-1):
for j in range(0, width-1):
#relief effect
relief_value = np.sum(gray_img[i:i + 2, j:j + 2] * relief_filter) + 128
relief_value = 255 if relief_value > 255 else relief_value
relief_value = 0 if relief_value < 0 else relief_value
relief_img[i, j] = relief_value
#sculpt effect
sculpt_value = np.sum(gray_img[i:i + 2, j:j + 2] * sculpt_filter) + 128
sculpt_value = 255 if sculpt_value > 255 else sculpt_value
sculpt_value = 0 if sculpt_value < 0 else sculpt_value
sculpt_img[i, j] = sculpt_value
cv2.namedWindow('Relief Image', 0)
cv2.namedWindow('Sculpt Image', 0)
cv2.imshow('Relief Image', relief_img)
cv2.imshow('Sculpt Image', sculpt_img)
cv2.waitKey(0)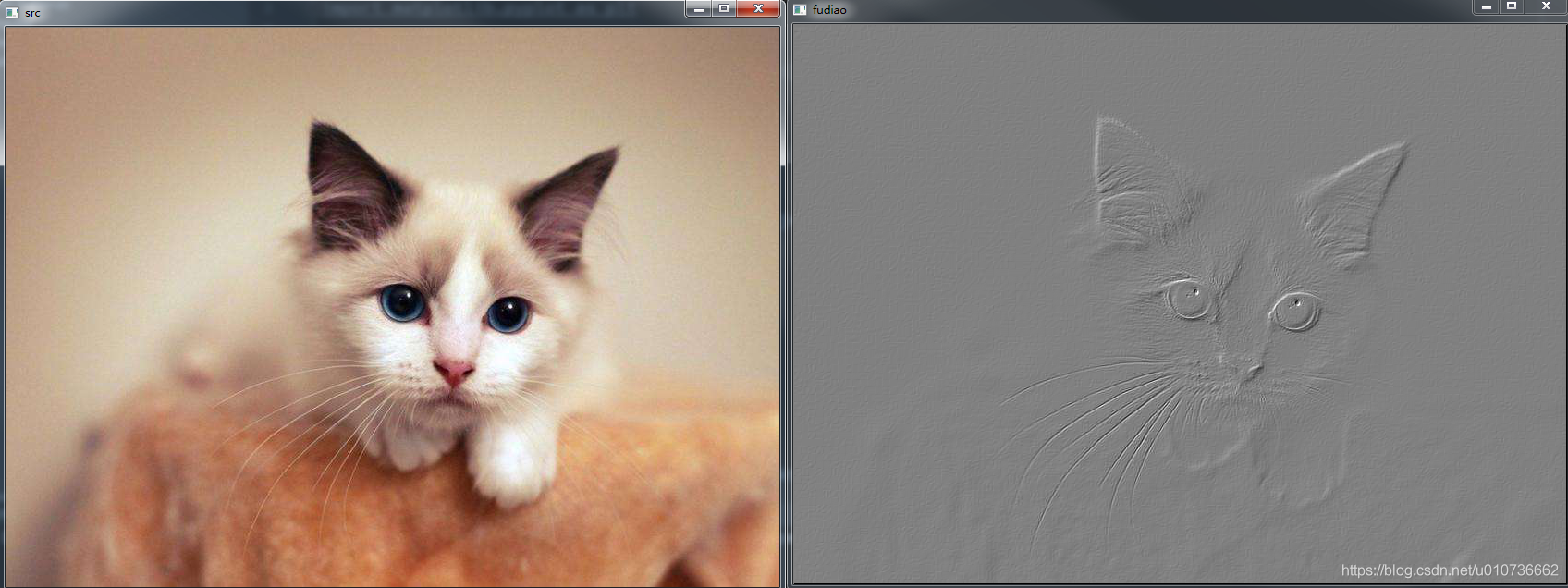
4.10 颜色映射
图像颜色映射的实质是色彩通道的变换计算,即通过对图像的颜色通道值进行修改实现图像的颜色映射,说白了就是用新的bgr值替换掉旧的bgr值。
import cv2
import numpy as np
image = cv2.imread("wuhuan.jpg", 1)
cv2.imshow('image', image)
image_info = image.shape
height = image_info[0]
width = image_info[1]
dst = np.zeros((height, width, 3), np.uint8)
for i in range(height):
for j in range(width):
(b, g, r) = image[i, j]
b = b * 1.5 #蓝色增强
if b > 255:
b = 255
dst[i, j] = (b, g, r)
cv2.imshow('dst', dst)
# cv2.imshow("dst",dst)
cv2.waitKey()上述代码中,我们遍历原图像的像素点,并将像素点的蓝色通道值进行增强,具体来说,就是将bgr中的b(蓝色通道)值在原基础上乘以1.5。当然,颜色通道值的范围为0~255,因此对于乘积结果我们需要做范围判断,对于超过255的结果需要置为255。


4.11 彩色映射
与图像颜色映射用于增强某个或某几个颜色通道值不同的是,图像彩色映射主要应用于灰度图,并利用色度图产生伪彩色图像。
例如,假设我们想在地图上显示不同地区的温度。我们可以把地图上不同地区的温度数据叠加为灰度图像。其中,温度较低的地方用较暗的区域表示,温度较高的地区用较亮的区域表示。这样就形成了一个温度数据图像。这样的图像是很有意义的,我们能通过颜色的变化更好地感知不同区域温度的高地。除此之外,还有高度、压力、密度、湿度等我们都可以通过将其转换为彩色数据图像以实现数据的可视化。
OpenCV中一共定义了12种色度图,可以应用于灰度图像,产生不同的伪彩色图像。

上图中显示了一个关于色度图的视觉表示及OpenCV中的对应数值,其中,颜色条从左到右分别表示灰度值从小到大,即越小的灰度值将呈现越靠左边的颜色。
OpenCV中使用applyColorMap(src,colormap,dst=None)函数来产生伪彩色图像
import cv2
image = cv2.imread("wuhuan.jpg",1)
gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',gray)
colormap=cv2.applyColorMap(gray,cv2.COLORMAP_JET) #彩色映射--制作伪彩色图像
'''
参数1 src:必选参数。表示输入的原图像数组,原图像必须为灰度图或者是CV_8UC1、CV_8UC的彩色图
参数2 colormap:必选参数。用于设置图像彩色映射的参考色度图
'''
cv2.imshow('color',colormap)
cv2.waitKey()效果图:


第5章 计算机视觉加强之图像绘制
5.1 形状绘制
5.1.1 线段绘制
在使用OpenCV处理图像时,我们有时候会需要在图像上画线段、矩形等。OpenCV中使用
line(img,pt1,pt2,color,thickness=None,lineType=None,shift=None)函数进行线段的绘制
- 参数2和参数3 pt1,pt2:必选参数。线段的坐标点,分别表示起始点和终止点
- 参数4 color:必选参数。用于设置线段的颜色
- 参数5 thickness:可选参数。用于设置线段的宽度
- 参数6 lineType:可选参数。用于设置线段的类型,可选8(8邻接连接线-默认)、4(4邻接连接线)和cv2.LINE_AA 为抗锯齿
import cv2
import numpy as np
new_ImageInfo = (500, 500, 3)
dst = np.zeros(new_ImageInfo, np.uint8)
cv2.line(dst, (0, 0), (300, 300), (0, 0, 255))
cv2.line(dst, (290, 430), (330, 305), (255, 0, 255), 30)
cv2.line(dst, (190, 430), (230, 305), (0, 255, 255), 30, cv2.LINE_AA)
cv2.imshow('dst', dst)
cv2.waitKey(0)5.1.2 矩形绘制
OpenCV中为我们提供了绘制矩形的函数
rectangle(img,pt1,pt2,color,thickness=None,lineType=None,shift=None)- 参数2和参数3 pt1,pt2:必选参数。矩形的顶点,分别表示顶点与对角顶点,即矩形的左上角与右下角(这两个顶点可以确定一个唯一的矩形)
- 参数4 color:必选参数。用于设置矩形的颜色
- 参数5 thickness:可选参数。用于设置矩形边的宽度,当值为负数时,表示对矩形进行填充
- 参数6 lineType:可选参数。用于设置线段的类型,可选8(8邻接连接线-默认)、4(4邻接连接线)和cv2.LINE_AA 为抗锯齿
import cv2
import numpy as np
#矩形的绘制
new_ImageInfo = (500, 500, 3)
dst = np.zeros(new_ImageInfo, np.uint8)
cv2.rectangle(dst, (0, 0), (300, 300), (0, 0, 255))
cv2.rectangle(dst, (290, 430), (330, 305), (255, 0, 255), -1)
cv2.rectangle(dst, (190, 430), (230, 305), (0, 255, 255), 2, cv2.LINE_AA)
cv2.imshow('dst', dst)
cv2.waitKey(0)5.1.3 圆形绘制
cv2.circle(img, center, radius, color, thickness, lineType, shift)img:要画的圆所在的矩形或图像
center:圆心坐标
radius:圆的半径值
color:圆边框颜色,颜色值为BGR,即:(0,0,255)为红色
thickness:圆边框大小,负值表示该圆是一个填充图形
lineType:线条类型,三个参数可选0,4,8,感兴趣的亲测
shift:圆心坐标和半径的小数点位数
【注】img、center、radius、color为必须参数,其它为可选项。
import cv2
import numpy as np
#圆形的绘制
new_ImageInfo = (500, 500, 3)
dst = np.zeros(new_ImageInfo, np.uint8)
cv2.circle(dst, (100, 90), 50, (255, 0, 255), -1)
cv2.circle(dst, (190, 250), 100, (0, 255, 255), 2, cv2.LINE_AA)
cv2.imshow('dst', dst)
cv2.waitKey(0)5.1.4 椭圆形绘制
cv2.ellipse(img, center, axes, rotateAngle, startAngle, endAngle, color, thickness, lineType, shift)img:要画的椭圆所在的矩形或图像
center:椭圆的圆心坐标,注意这是一个坐标值
axes:椭圆的长轴和短轴的长度,这是一个元组信息
rotateAngle:椭圆旋转的角度
startAngle:椭圆弧起始角度
endAngle:椭圆弧终止角度
color:椭圆线条颜色,颜色值为BGR,即:(0,0,255)为红色
thickness:椭圆的线条宽度
lineType:线条类型,三个参数可选LINE_4、LINE_8、LINE_AA,感兴趣的可以亲测
shift:椭圆坐标点小数点位数
5.1.5 多边形绘制
cv2.polylines(img, pts, isClosed, color, thickness, lineType, shift)img:多边形所在的矩形或图像
pts:多边形各边的坐标点组成的一个列表,是一个numpy的数组类型
isClosed:值为True或False,若为True则表示一个闭合的多边形,若为False则不闭合
color:线条颜色,颜色值为BGR,即:(0,0,255)为红色
thickness:线条宽度
lineType:线条类型,三个参数可选LINE_4、LINE_8、LINE_AA,感兴趣的可以亲测
shift:坐标点小数点位数
import numpy as np
import cv2
# 多边形绘制
img = np.zeros((512, 512, 3), np.uint8)
pts = np.array([[100, 50], [200, 300], [70, 20], [250, 250], [500, 100]], np.int32)
pts = pts.reshape((-1, 1, 2))
cv2.polylines(img, [pts], True, (0, 255, 255))
cv2.imshow('line', img)
cv2.waitKey()5.2 文字绘制
cv2.putText(img, text, org, fontFace, fontScale, color, thickness, lineType, bottomLeftOrigin)img:文字要放置的矩形或图像
text:文字内容
org:文字在图像中的左下角坐标
fontFace:字体类型,可选参数有以下几种
FONT_HERSHEY_SIMPLEX,FONT_HERSHEY_PLAIN,FONT_HERSHEY_DUPLEX,FONT_HERSHEY_COMPLEX, FONT_HERSHEY_TRIPLEX, FONT_HERSHEY_COMPLEX_SMALL, FONT_HERSHEY_SCRIPT_SIMPLEX, orFONT_HERSHEY_SCRIPT_COMPLEX
上述类型的字体可以结合 FONT_HERSHEY_ITALIC一起来使用,从而使字体产生斜体效果。
fontScale:缩放比例,用该值乘以程序字体默认大小即为字体大小
color:字体颜色,颜色值为BGR,即:(0,0,255)为红色
thickness:字体线条宽度
lineType: 线条类型。为了更好看,建议使用lineType = cv.LINE_AA。
bottomLeftOrigin:默认为 true,即表示图像数据原点在左下角;若为False则表示图像数据原点在左上角。
【注】color(含)之前的参数为必须参数,其它为可选项。
import cv2
import numpy as np
#文字的绘制
img = np.zeros((512, 512, 3), np.uint8)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, 'I love Chestnut!!', (120, 250), font, 1, (0, 0, 255), 2, cv2.LINE_AA, False)
cv2.imshow('show', img)
cv2.waitKey()5.3 图像绘制
import cv2
#图形的绘制
img1 = cv2.imread('../timgjpg.jpg', 1)
img2 = cv2.imread('../timg.jpg', 1)
height = int(img2.shape[0] * 0.3)
width = int(img2.shape[1] * 0.3)
img2 = cv2.resize(img2, (width, height))
for i in range(0, height):
for j in range(0, width):
img1[100 + i, 100 + j] = img2[i, j]
cv2.imshow('img1', img1)
cv2.waitKey()第6章 机器学习
6.1 视频分解图片
import cv2.cv2 as cv
cap = cv.VideoCapture('../fruits.mp4')
isOpened = cap.isOpened
print(isOpened)
i = 0
while isOpened:
if i == 100:
break
else:
i = i + 1
(flag, frame) = cap.read()
frame = cv.flip(frame, -1)
filename = 'image'+str(i)+'.jpg'
print(filename)
if flag:
cv.imwrite(filename, frame, [cv.IMWRITE_JPEG_QUALITY, 100])
print('end!')6.2 图片合成
import cv2.cv2 as cv
import os
picexp = r'F:\yolo\keras-yolo3-underwater\VOCdevkit\VOC2007\JPEGImages\000000.jpg'
img = cv.imread(picexp, 1)
path = r'F:\yolo\keras-yolo3-underwater\VOCdevkit\VOC2007\JPEGImages'
size = (img.shape[1], img.shape[0])
print(size)
fourcc = cv.VideoWriter_fourcc(*'MJPG')
VideoWriter = cv.VideoWriter('../sea.avi', fourcc, 30.0, size)
filelist = os.listdir(path)
for picfile in filelist:
picpath = os.path.join(path, picfile)
print(picpath)
img = cv.imread(picpath, 1)
VideoWriter.write(img)
cv.imshow('frame', img)
if cv.waitKey(1) & 0xFF == ord('q'):
break
print('end!')
VideoWriter.release()
cv.destroyAllWindows()6.3 Haar特征
Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。它分为三类:边缘特征、线性特征、中心特征和对角线特征。用黑白两种矩形框组合成特征模板,在特征模板内用 黑色矩形像素和 减去 白色矩形像素和来表示这个模版的特征值。例如:脸部的一些特征能由矩形模块差值特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。但矩形特征只对一些简单的图形结构,如边缘、线段较敏感,所以只能描述在特定方向(水平、垂直、对角)上有明显像素模块梯度变化的图像结构。
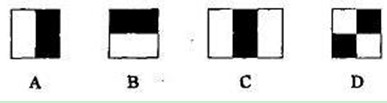
如上图A、B、D模块的图像Haar特征为:
$$
v=Sum白-Sum黑
$$
C 模块的图像Haar特征为:
$$
v=Sum白(左)+Sum白(右)-2*Sum黑
$$
这里要保证白色矩形模块中的像素与黑色矩形的模块的像素数相同,所以乘2
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!