One-Stage目标检测算法——开创性的YOLO
Faster R-CNN系列等两阶段(Two-Stage)的目标检测算法有较好的检测效果和较高的检测精度,但从速度上来讲满足不了实时检测的要求。基于回归方法的深度学习目标检测就显得尤为重要了。使用回归的思想,输入的图片经过网络直接计算出物体的分类,位置信息以达到目标检测的目的。
YOLO(You only look once:Unified ,Real-Time Object Detection)是基于回归的方法中最经典的算法之一。YOLO采用单个神经网络全图直接训练预测物品边界和类别概率,模型的最后直接输出Bounding-box 的坐标、 Bounding-box 中包含物体的置信度和物体的类别。从而实现真正意义上的端到端的物品检测。识别性能有了很大提升,在 Titan X 的 GPU 上能达到45 FPS,而在Fast YOLO(卷积层更少)中,可以达到155 FPS。
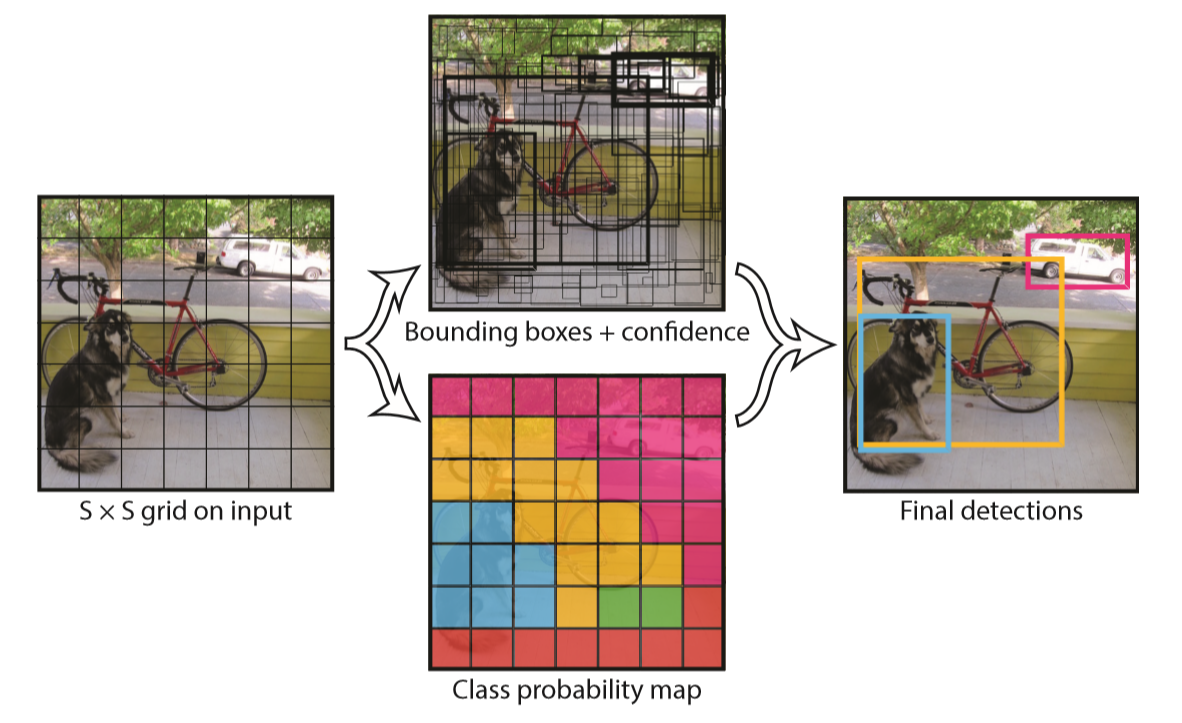
YOLO预测阶段的流程如下,流程图如图1所示:
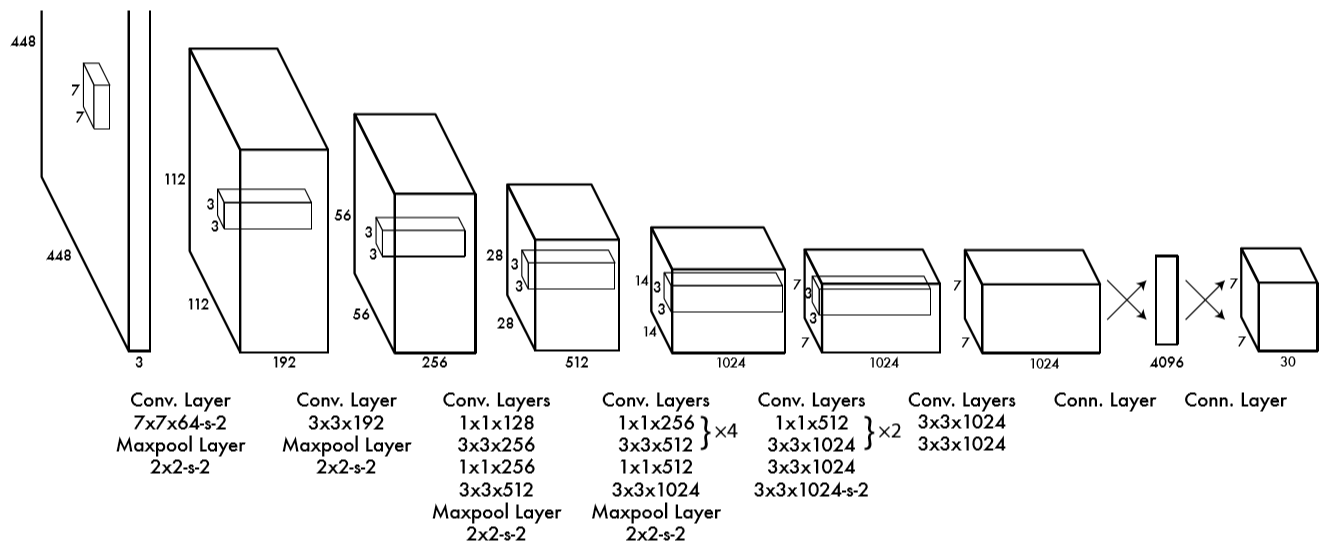
1) 将图像缩放到448×448尺寸作为卷积神经网络的输入,并对图像划分成S×S的网格。
2) 经过CNN后到达FC层,最后一层的FC输出4096个神经元
3) FC层的输出作为检测层(Detection层)的输入,在1)中将原图分为7×7的网格,对于每个网格,我们都预测B个Bounding-box,包括每个Bounding-box的4个位置信息,网格包含目标的置信度。另外每个网格还预测C个类别上的概率。最终得到
$$
S×S×(B×5+C)
$$
大小的特征图,输出的特征图结构如下。
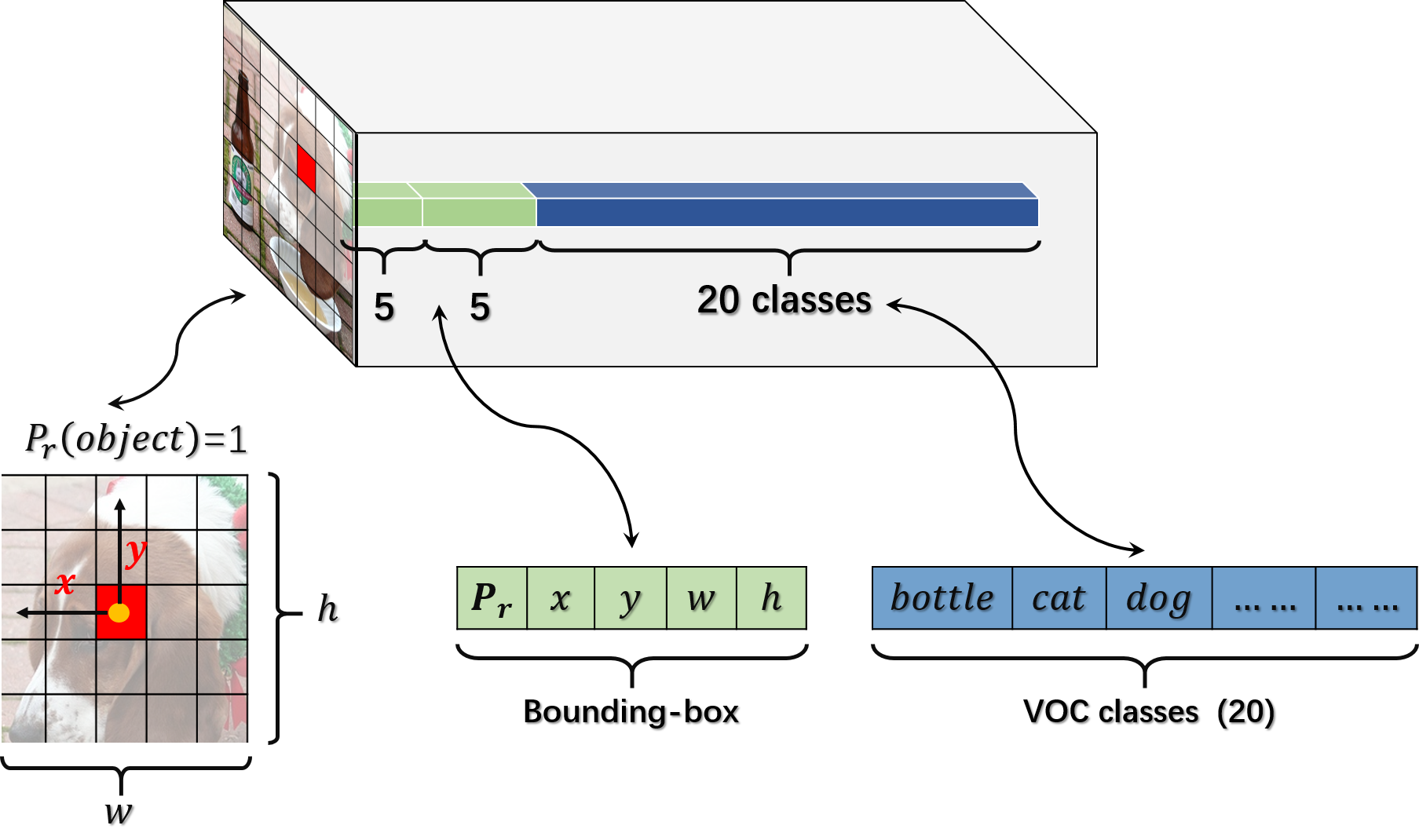
YOLO在PASCAL VOC数据集上进行评估,数据集中类别有C=20个。所以输出的特征向量大小为
$$
S×S×(B×5+C) = 7×7×(2×5+20)=(7,7,30)
$$
YOLO网络模型的架构思想如图3所示,我们将初始大小为448×448大小的图像分为7×7的网格,每个网格的大小为64×64。如果一个物体的中心点落在这个网格内,那么这个网格负责预测这个物体。每个网格预测两个Bounding-box,每个Bounding-box对应预测除了四个位置参数外,还有一个参数叫置信度(confidence)的值,表达式为如下所示:
$$
confidence= P_r (Object)×IOU(truth|pred)
$$
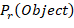 表示这个网格是否包含目标物体,若包含目标物体则
表示这个网格是否包含目标物体,若包含目标物体则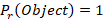 ,否则
,否则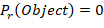 。
。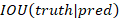 表示ground truth和prediction的重叠率。还会预测出网格中存在目标物体的条件下属于那一类别物体的后验概率!
表示ground truth和prediction的重叠率。还会预测出网格中存在目标物体的条件下属于那一类别物体的后验概率!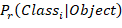 。
。
$$
Score=confidence×P_r (Class_i |Object)=P_r (Class_i )×IOU(truth|pred)
$$
| Real-Time Detectors | Train | mAP | FPS |
|---|---|---|---|
| Fast YOLO | 2007+2012 | 52.7 | 155 |
| YOLO | 2007+2012 | 63.4 | 45 |
| Less Than Real-Time | Train | mAP | FPS |
|---|---|---|---|
| Fast R-CNN | 2007+2012 | 70.0 | 0.5 |
| Faster R-CNN VGG-16 | 2007+2012 | 73.2 | 7 |
- YOLO的每一个网格只预测两个边界框,一种类别。这导致模型对相邻目标预测准确率下降。因此,YOLO对集群的目标或小的目标识别准确率较低。
- 损失函数会同样的对待小边界框与大边界框的误差,导致了目标区域定位的误差偏大和召回率较低。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!