比较含退格的字符串
问题描述
给定 S 和 T 两个字符串,当它们分别被输入到空白的文本编辑器后,判断二者是否相等,并返回结果。 # 代表退格字符。
注意:如果对空文本输入退格字符,文本继续为空。
示例 1:
输入:S = "ab#c", T = "ad#c" 输出:true 解释:S 和 T 都会变成 “ac”。
示例 2:
输入:S = "ab##", T = "c#d#" 输出:true 解释:S 和 T 都会变成 “”。
示例 3:
输入:S = "a##c", T = "#a#c" 输出:true 解释:S 和 T 都会变成 “c”。
示例 4:
输入:S = "a#c", T = "b" 输出:false 解释:S 会变成 “c”,但 T 仍然是 “b”。
提示:
1 <= S.length <= 2001 <= T.length <= 200S和T只含有小写字母以及字符'#'。
进阶:
- 你可以用
O(N)的时间复杂度和O(1)的空间复杂度解决该问题吗?
解题思路
方法一:直接比较法
最简单的方法就是直接将两字符串中的#和其前一个字符去掉,比较剩余的字符是否相等。若相等则返回true。
我们如何在最好的时间内去掉#和其前一个字符呢?
在不考虑空间开销的情况下,我们可以考虑构造两个辅助栈来完成操作。如果遇到#,那么就取出栈顶的元素,这样也就模拟了删掉#前一个字符的效果。那么最后栈中剩余的元素就是去掉退格字符后的所有剩余字符。然后就可以将两个栈中的字符依次比较是否相同。这种方法的代码如下:
class Solution {
public boolean backspaceCompare(String S, String T) {
Stack<Character> stack1 = new Stack<>();
Stack<Character> stack2 = new Stack<>();
for(int i=0; i<S.length(); i++){
if(S.charAt(i)!='#') stack1.add(S.charAt(i));
else if(!stack1.isEmpty()) stack1.pop();
}
for(int j=0; j<T.length(); j++){
if(T.charAt(j)!='#') stack2.add(T.charAt(j));
else if(!stack2.isEmpty()) stack2.pop();
}
return stack1.equals(stack2);
}
}由于额外创建了两个辅助栈,所以时间复杂度还是有一些偏高。我们再尝试做一些改进:
那么本题,确实可以使用栈的思路,但是没有必要使用栈,因为最后比较的时候还要比较栈里的元素,有点麻烦。为了减轻开销,可以使用拼接字符串的方式将剩余的字符进行拼接,最后进行比较的是便是两个字符串。这样就会比比较两个集合的元素是否相同还要更快。
我们使用Java中的StringBuffer类来实现字符串的拼接。如果没有遇到#字符,则将该字符拼接到StringBuffer的对象中,否则删除StringBuffer对象的最后一个字符。最后返回两者对象的字符串进行比较。代码实现如下:
class Main {
public static void backspaceCompare(String S, String T) {
build(S).equals(build(T));
}
public static String build(String str) {
StringBuffer sb = new StringBuffer();
int len = str.length();
for (int i = 0; i < len; i++) {
if (str.charAt(i) != '#')
sb.append(str.charAt(i));
else if (sb.length() > 0)
sb.deleteCharAt(sb.length() - 1);
}
return sb.toString();
}
}两次的结果进行对比可以看到,从时间复杂度上,改进之后的方法执行时间更短。但是两次方法的内存消耗没有什么大的变化。有没有一种方法,既可以保持这种优秀的执行时间还保证内存消耗的更少呢?下面就介绍这种双指针的方法来减少内存消耗。
方法二:双指针法:
同时从后向前遍历S和T(i初始为S末尾,j初始为T末尾),记录#的数量,模拟消除的操作,如果#用完了,就开始比较S[i]和S[j]。
具体地,我们定义 skip 表示当前待删除的字符的数量。每次我们遍历到一个字符:
若该字符为退格符,则我们需要多删除一个普通字符,我们让
skip加1;若该字符为普通字符:
若
skip为0,则说明当前字符不需要删去;若
skip不为0,则说明当前字符需要删去,我们让skip减1。
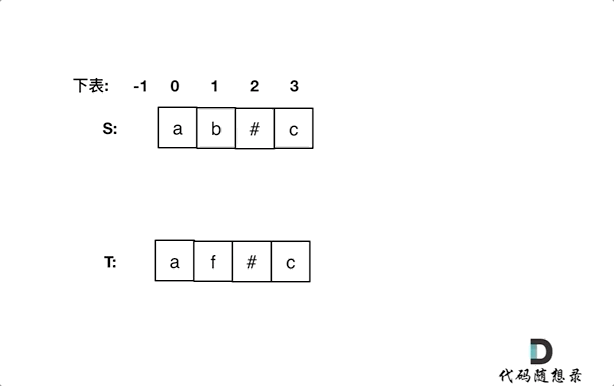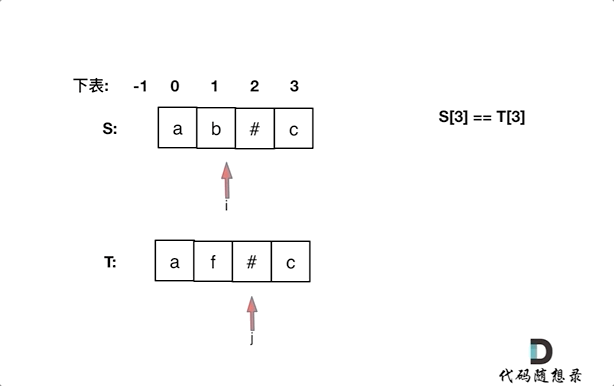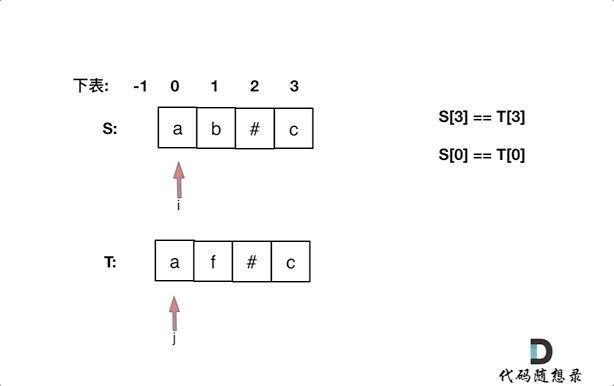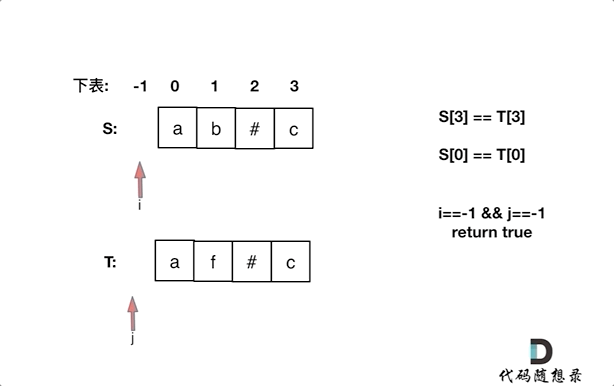
如果S[i]和S[j]不相同返回false,如果有一个指针(i或者j)先走到的字符串头部位置,也返回false。
代码实现
class Solution {
public boolean backspaceCompare(String S, String T) {
int skipS = 0, skipT = 0;
int i = S.length()-1, j = T.length()-1;
while(true){
while(i>=0){
if(S.charAt(i) == '#') skipS++;
else{
if(skipS>0) skipS--;
else break;
}
i--;
}
while(j>=0){
if(T.charAt(j) == '#') skipT++;
else{
if(skipT>0) skipT--;
else break;
}
j--;
}
if(i<0 || j<0) break;
if(S.charAt(i)!=T.charAt(j)) return false;
i--;j--;
}
if(i == -1 && j == -1) return true;
return false;
}
}复杂度分析
时间复杂度:O(N+M),其中 N 和 M 分别为字符串 S 和 T 的长度。我们需要遍历两字符串各一次。
空间复杂度:O(1)。对于每个字符串,我们只需要定义一个指针和一个计数器即可。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!