One-Stage目标检测算法——更好,更快,更强壮的YOLOv2
YOLO9000(YOLO9000:Better, Faster, Stronger)是YOLO算法的改进版,YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,所以称之为YOLO9000。
在保证目标召回率的同时,为了提高准确率和速度,YOLOv2并没有使用太深的网络这样也使得网络容易学习,主要做了以下几方面的改进:
- Batch Normalization:在每个卷积层中加入批归一化,使mAP有了
2%的提高。批归一化处理能够获得更好的收敛速度和收敛效果,减少过拟合的发生。 - High Resolution Classifier:采用
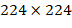 图像进行分类模型预训练后,再采用
图像进行分类模型预训练后,再采用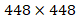 的高分辨率样本对分类模型进行
的高分辨率样本对分类模型进行10个epoch的微调,使网络特征逐渐适应的分辨率。然后再使用的检测样本进行训练,缓解了分辨率突然切换造成的影响。 - Anchor Boxes:引入Anchor Boxes的思想后,使原来的每张图片预测
98个Bounding-box增长到每张图片可以预测上千个Bounding-box。YOLOv2移除了全连接层、去掉了一个池化层,使网络卷积层输出具有更高的分辨率。同时减小输入图像的尺寸到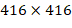 ,这样在下采样因子为
,这样在下采样因子为32的情况下,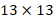 的特征图能正好有一个网格在正中心。相对YOLOv1的
的特征图能正好有一个网格在正中心。相对YOLOv1的81%的召回率,YOLOv2的召回率大幅提升到88%。同时mAP有0.2%的轻微下降。 - Dimension Clusters:对训练集中标注的边框进行
k-means聚类分析,设计出更符合样本中对象尺寸的先验框(Prior Boxes),这样就可以减少网络微调先验框到实际位置的难度。YOLOv2选择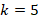 作为边框数量与
作为边框数量与IOU的折中。如图1所示。
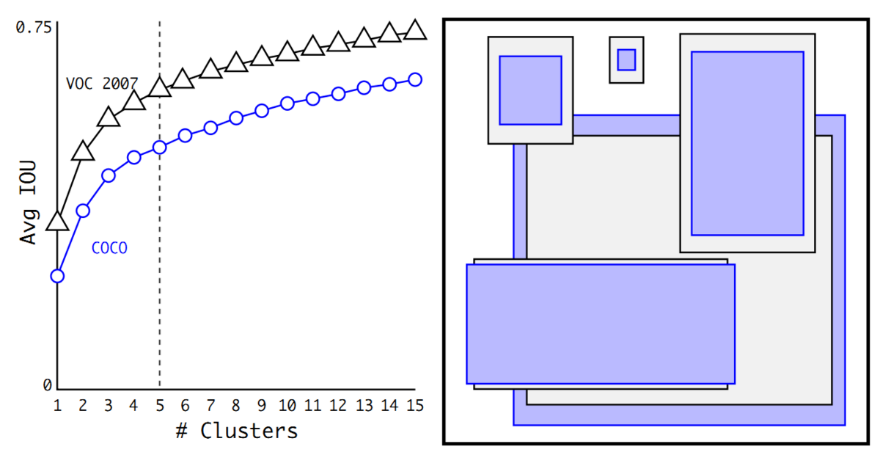
对比手工选择的Anchor Boxes,使用5个聚类得到的Prior Boxes即可达到61.0的Avg IOU,相当于9个手工设置的Anchor Boxes 60.9的Avg IOU。如下图2所示:
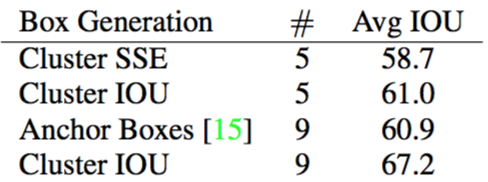
Direct Location Prediction:在使用Anchor Box时出现了预测边框的中心可能出现在任何位置的情况,导致训练早期阶段不容易稳定。因此YOLO调整了预测公式,将预测边框的中心约束在特定
gird网格内。预测边框的蓝色中心点被约束在蓝色背景的网格内。如图3所示,约束边框位置使得模型更容易学习,且预测更为稳定。这种方式将mAP提高了5%。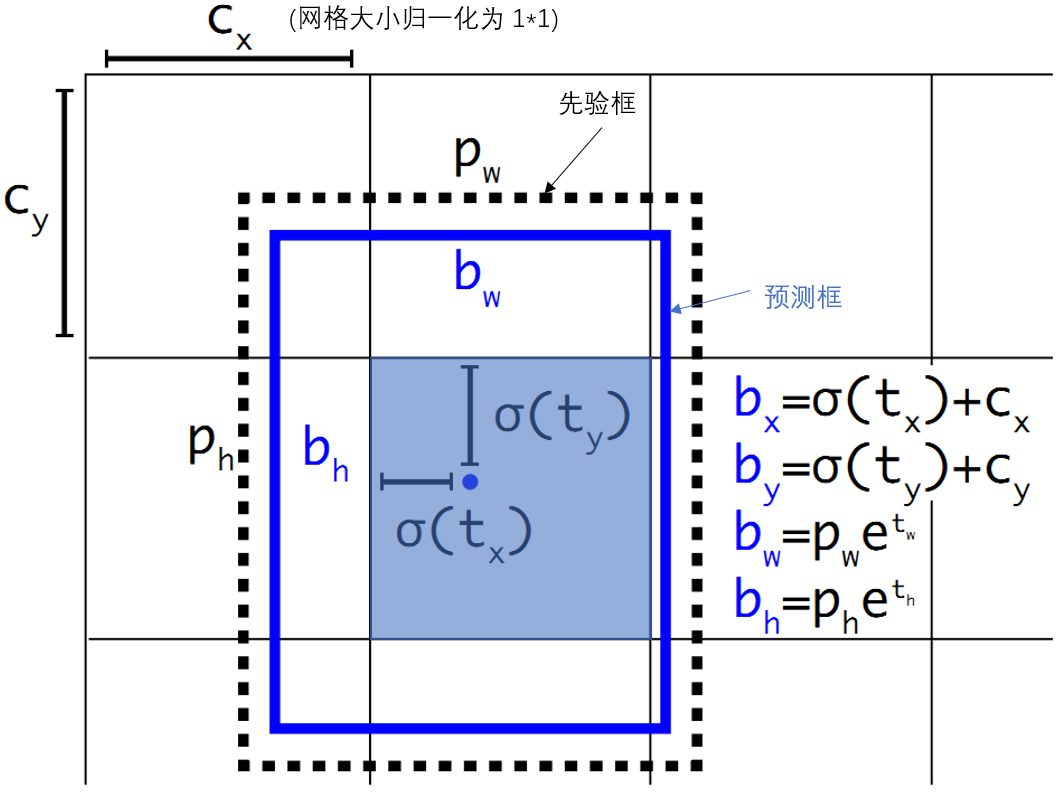 图3 利用Prior Box对预测框定位
图3 利用Prior Box对预测框定位Passthrough Layer: 输入
经过卷积网络下采样最后输出是,较小的对象可能特征已经不明显甚至被忽略掉了。为了更好的检测出一些比较小的对象,YOLOv2引入一种称为passthrough层的方法在特征图中保留上一次池化之前的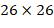 的特征。也就是说将
的特征。也就是说将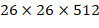 的特征图转化为
的特征图转化为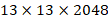 。然后直接传递到
。然后直接传递到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出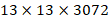 的特征图,使得MAP提高了
的特征图,使得MAP提高了1%。Multi-Scale Training:为了能使YOLOv2在不同尺寸的图片上鲁棒性更强,这里加入了多尺度的图像训练。因为去掉了全连接层,YOLOv2可以输入任何尺寸的图像。因为整个网络下采样倍数是
32,作者采用了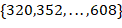 等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是
等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是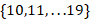 。训练时每
。训练时每10个batch就随机更换一种尺寸,使网络能够适应各种大小的对象检测。
第一阶段就是先预训练Darknet-19,模型输入为
224×224,共训练160个epochs。第二阶段将网络的输入调整为
448×448,继续finetune分类模型。第三个阶段就是修改Darknet-19分类模型为检测模型,移除最后一个卷积层、global avg pooling层以及softmax层,并且新增了三个
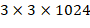 卷积层,同时增加了一个passthrough层,最后使用
卷积层,同时增加了一个passthrough层,最后使用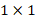 卷积层输出预测结果,输出的channels数为:
卷积层输出预测结果,输出的channels数为: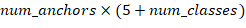 。由于Anchors数为
。由于Anchors数为5,对于VOC数据集(20种分类对象)输出的channels数就是125,最终的输出的特征大小为:
$$
(13, 13, 5,25)
$$
| Detection Frameworks | Train | mAP | FPS |
|---|---|---|---|
| YOLO | 2007+2012 | 63.4 | 45 |
| Fast R-CNN | 2007+2012 | 70.0 | 0.5 |
| Faster R-CNN VGG-16 | 2007+2012 | 73.2 | 7 |
| YOLOv2 288×288 | 2007+2012 | 69.0 | 91 |
| YOLOv2 352×352 | 2007+2012 | 73.7 | 81 |
| YOLOv2 416×416 | 2007+2012 | 76.8 | 67 |
| YOLOv2 480×480 | 2007+2012 | 77.8 | 59 |
| YOLOv2 544×544 | 2007+2012 | 78.6 | 40 |
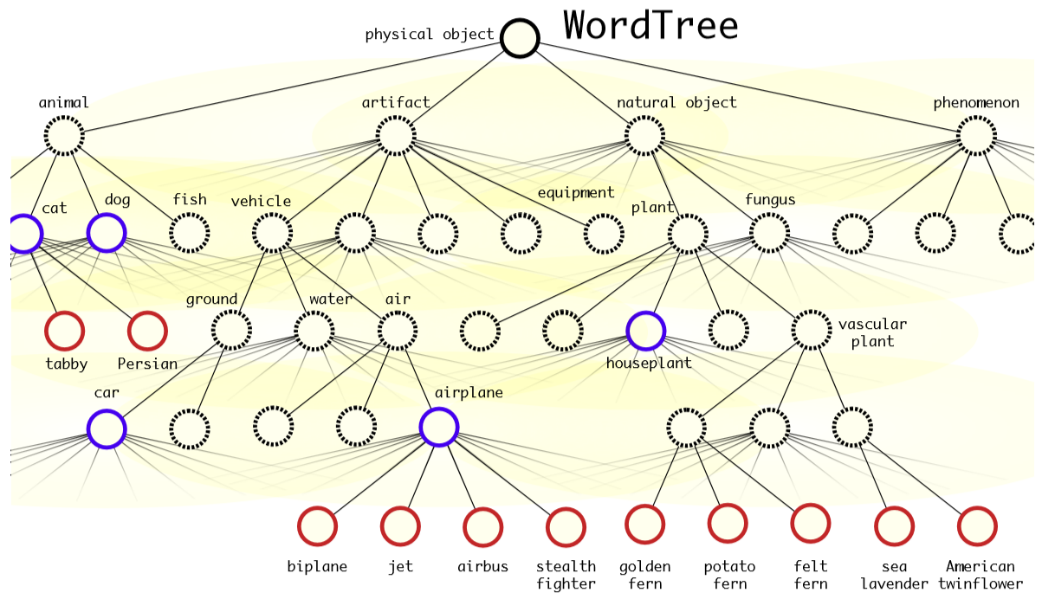
对于单个节点,属于它的所有子节点之间是互斥关系,所以计算上可以进行softmax操作。实际中每个节点下的所有子节点都会进行softmax.
有标签的样本对应的WordTree中,该对象节点到根节点的所有节点概率都是1,其它节点概率是0。根据训练标签的设置,其实模型学习的是各节点的条件概率。
$$
Pr(Norfolk terrier)=Pr(Norfolk terrier│terrier)×Pr(terrier│hunting dog)
$$
$$
×…×Pr(mammal│animal)×Pr(animal|physical object)
$$
为了计算简便,从根节点开始向下遍历,对每一个节点,在它的所有子节点中,选择概率最大的那个,一直向下遍历直到某个节点的子节点概率低于设定的阈值,或达到叶子节点,那么该节点就是该WordTree对应的对象。
YOLO9000依然采用YOLOv2的网络结构,使用3个先验框,现在YOLO9000的输出是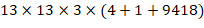 。由于对象分类改成WordTree的形式,相应的误差计算也需要一些调整。对一个检测样本,其分类误差只包含该标签节点以及到根节点的所有节点的误差。对于分类样本,则只计算分类误差。YOLO9000总共输出
。由于对象分类改成WordTree的形式,相应的误差计算也需要一些调整。对一个检测样本,其分类误差只包含该标签节点以及到根节点的所有节点的误差。对于分类样本,则只计算分类误差。YOLO9000总共输出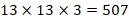 个预测框,计算它们对样本标签的预测概率,选择概率最大的那个框负责预测该样本的对象,即计算其WordTree的误差。
个预测框,计算它们对样本标签的预测概率,选择概率最大的那个框负责预测该样本的对象,即计算其WordTree的误差。
总的来说,YOLOv2通过一些改进明显提升了预测准确性,同时继续保持其运行速度快的优势。YOLO9000则开创性的提出联合使用分类样本和检测样本的训练方法,使对象检测能够扩展到缺乏检测样本的对象。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!